
Web Pages - Efficient Paging Without The WebGrid
Web Pages - Efficient Paging Without The WebGrid
If you want to display your data over a number of pages using WebMatrix Beta1, you have two options. One is to use the built-in paging support that comes with the WebGrid helper. But that means that your data will be displayed within an HTML table. If that is not your preferred layout choice, you need to write your own paging code. Let‘s look at how you can do that.
Actually, there is another problem with paging within the WebGrid helper apart from being restricted to html tables, and that is that‘s it‘s not particularly efficient out of the box. If you have 10,000 rows of data, and you want to display 10 rows per page, all 10,000 rows are retrieved from the database for each page. The pager works out how to only show the current 10, and wastes the other 9,990 rows. That‘s a fair sized overhead on each page. Ideally, you should only retrieve the data you need for each page. Sql Server CE 4.0 offers OFFSET and FETCH, which enable paging queries.
I‘m going to add a page to the Books application I introduced in my first look at WebMatrix. I‘ve called it Paging.cshtml. If you followed the second of my WebMatrix articles, you should already know that I have fiddled around with the original download and added some support for layout pages and so on to create a consistent look and feel. So if you are using the download as a basis to add paging functionality, you may want to quickly look at what I described in the second article, or just go to the bottom of this article to get the updated download. Back to Paging.cshtml, I have removed all the default markup so that this page becomes a content page. At the top of the page, I declare a number of variables:
var pageSize = 3; var totalPages = 0; var count = 0; var page = UrlData[0].AsInt(1); var offset = (page -1) * pageSize;
The first variable is pageSize. This dictates how many records per page I want to display. I‘ve set it at 3. totalPages will be used to calculate how many pages of data there are in the database that match the selection criteria. count will be used to store the total number of matching records that match the selection criteria. page is used to identify what the current page is. It will actually obtain its value from the URL of the page. I‘ve decided to take advantage of the built in routing support that comes with Web Pages, but more of that a bit later. The current page defaults to 1 if no value is present. Finally, offset will be used to specify how many rows of data within the database should be ignored before the current "page" of data is retrieved. The calculation for offset‘s value is actually quite straightforward. If the current page is 1, offset will equal 1 - 1 * 3. Since that results in zero, no rows of data will be skipped. If the current page is determined to be 3, offset will equal 3 - 1 * 3 (or 6). In other words, we want to ignore rows 1 - 6 and show rows 7, 8 and 9 on page 3.
We need to get the total number of records that can be displayed, first. This will be used to calulcate the totalPages.
var db = Database.Open("Books");
var sql = "Select Count(*) From Books " +
"Inner Join Authors on Books.AuthorId = Authors.AuthorId " +
"Inner Join Categories on Books.CategoryId = Categories.CategoryId";
count = (int)db.QueryValue(sql);
totalPages = count/pageSize;
if(count % pageSize > 0){
totalPages += 1;
}
If you only want a single value returned from the database query, Database.QueryValue() is the method that should be used. It returns something of type object, which needs to be cast to the correct type (in this case an int) for you to be able to work with it. The code above simply returns a number, containing the COUNT of all matching rows in the database. That‘s divided by the number of records per page, and the result is the total number of full pages of 3 records available. The modulus operator (%) is also used here to calculate whether there are still records left over after the previous division because it rounds down. If there are, another page is added to totalPages to take account of these extra records.
Now we have all the elements required to calculate the pages of data needed, and which page the user is on. All that‘s needed is a way to pass this information to the SQL query which is responsible for getting the current page of data:
sql = "Select Title, ISBN, Description, FirstName, LastName, Category From Books " +
"Inner Join Authors on Books.AuthorId = Authors.AuthorId " +
"Inner Join Categories on Books.CategoryId = Categories.CategoryId " +
"Order By BookId OFFSET @0 ROWS FETCH NEXT @1 ROWS ONLY;";
var result = db.Query(sql, offset, pageSize);
This query shows the OFFSET and FETCH keywords in use. As I alluded to earlier, OFFSET is the starting point at which records should be retrieved, and FETCH dictates how many should be retrieved. OFFSET and FETCH need an ORDER BY clause to be able to work, so I decided to order the results by the BookId value. @0 and @1 are parameter markers. This allows for values to be passed in dynamically, and is the preferred way to pass in variable values to a SQL query.
I mentioned earlier that the current page is calculated from the URL, and that I have taken advantage of the inbuilt support that for Routing that comes with Web Pages. Now is the time to examine that in a bit more detail. Routing is a mechnism whereby URLS are mapped to resources on the web server. The whole topic deserves more explanation than I am going to give here, but fundamentally, a URL of www.mysite.com/Paging will map to www.mysite.com/Paging.cshtml. Equally, www.mysite.com/Paging/3 can be used to request page 3 of the data. The /3 part of the url is available within UrlData, which is a zero based collection. Referencing the element within the collection by its index is done by putting the index in square brackets: UrlData[indexvalue]. So UrlData[0] in this case will return the current page number from the address in the browser. So, if we run the query having requested page 3. it translates to "Get me these records, offsetting the first 6 rows, and only fetch the next 3 rows".
The next bit of code shows how the records are to be displayed, but at the top of this page, I have also added a bit of code which shows the user which page they are currently on, and how many pages there are in total:
<p>Page @page of @totalPages</p>
@foreach(var row in result){
<h2>@row.Title</h2>
<p><strong>Author:</strong> @row.FirstName @row.LastName<br />
<strong>ISBN:</strong> @row.ISBN <br/>
<strong>Description:</strong> @row.Description <br />
<strong>Category: </strong> @row.Category</p>
}
Finally, we need some paging links. These will be responsible for ensuring that the correct page number appears in the URL so that the user can navigate the records successfully.
@{
for (var i = 1; i < totalPages + 1; i++){
<a href="/Paging/@i">@i</a>
}
}
This code sets up a counter to loop through from 1 to the total number of pages, and writes a link for each page of data. When you first run the page, by hitting F12 or clicking the Launch button, you will see the first 3 records in the database appear, and you can also see that the URL in the browser address bar is Paging.cshtml.
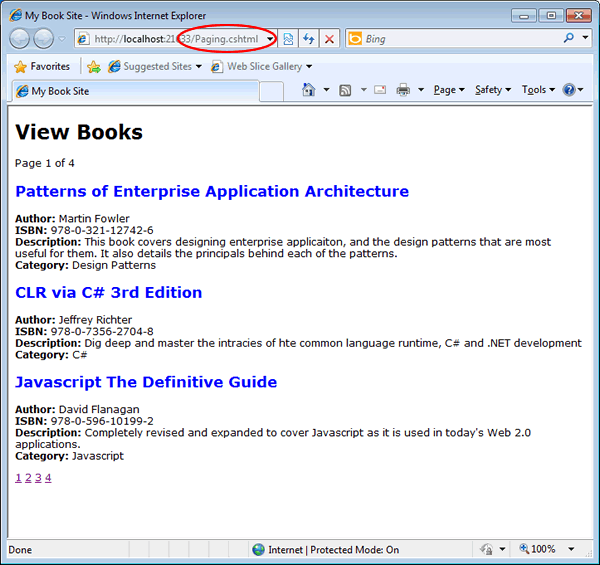
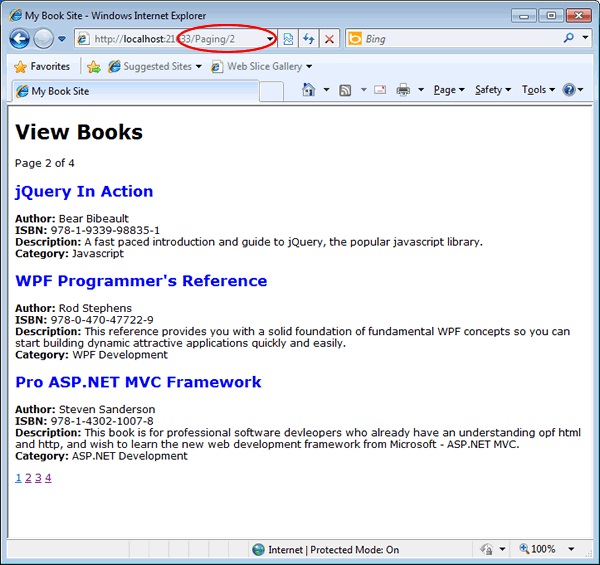
If you click the second paging link, you should see that change to Paging/2, and routing come into play.
Download the code from here. To run it, simply unzip the folder, and then use the Create Site From Folder option in WebMatrix.
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































