
第七章、epub文件处理 -- 解析 .xhtml文件 (一)
第七章、epub文件处理 -- 解析 .xhtml文件 (一)
本章将介绍代码如何利用ZLTextPlainModel类来分别处理.xhtml文件中的文本信息与标签信息。
本章涉及的核心类是ZLTextPlainModel类、ZLTextWritablePlainModel类、CachedCharStorage类、XHTMLTagAction接口实现类
.xhtml文件中包含着两种信息:文本信息与标签信息。我们需要先正确解析出标签信息代表的结构,才能正确得将文本信息显示在屏幕上。
举个例子:(这个例子是三体1中的文本)

我们需要让程序知道这里有四种标签(h1标签、h2标签、b标签、p标签),每种标签代表了不同的格式。程序必须正确显示出不同标签的格式,才能让用户看到正常的文本信息。

在正式开始介绍对.xhtml文件中的文本信息与标签信息的处理流程之前,我们有必要先来介绍下流程中涉及的三个核心类:ZLTextWritablePlainModel类、CachedCharStorage类、XHTMLTagAction接口实现类
ZLTextWritablePlainModel类:
ZLTextWritablePlainModel类是ZLTextPlainModel类的子类,这个类中有三个int数组与一个CachedCharStorage类。
myStartEntryIndices属性指向的int数组记录了每个段落具体在CachedCharStorage类内部的哪一个char数组里面;
myStartEntryOffsets属性指向的int数组记录了每个段落从CachedCharStorage类内部char数组的哪个位置开始;
myParagraphLengths属性指向的int数组记录每个段落在CachedCharStorage类内部char数组中占据多少长度;
最后,myStorage属性指向的CachedCharStorage类内部的char数组则是实际存储文本信息与标签信息的地方
PS:FBReader程序中一组p标签就代表一个段落(Paragraph)。

CachedCharStorage类:
这个类中有两个重要的属性:myArray属性、myBlockSize属性
myArray属性指向一个由char数组组成的ArrayList(char数组都设定为软引用WeakReference,保证了虚拟机会回收这些char数组,不会占用过多的内存)。这些char数组里面的元素就代表这.xhtml的文本信息与标签信息。
myBlockSize属性指向一个int。char数组的长度最长不会超过这个长度(65536),一旦超过这个长度,代码就会新建一个char数组,同时就的数组会被持久化以便以后再用。

XHTMLTagAction接口实现类:
epub文件中有很多标签,不同的标签代表不同的不同的结构,所以FBReader也为不同的标签提供了不同的处理类。这些处理类都是XHTMLTagAction接口的实现类。
标签一般都是成对出现的,XHTMLTagAction接口中的两个方法分别就对应了

具体哪些类对应哪些标签,是由XHTMLReader类中fillTagTable方法定义的。

介绍完三个核心类,我们就可以正式开始介绍对.xhtml文件中的文本信息与标签信息的处理流程了。
我们先以处理一个标签对(包含起始标签和结束标签)的流程为例。在利用for循环迭代标签对转换成的char数组的过程中ZLXMLParser类的doIt方法会对以下的节点调用XHTMLReader类进行操作
起始标签右边的“<”:
记录char数组的偏移量,调用ZLXMLReader接口characterDataHandlerFinal方法(XHTMLReader类并未实现该方法,故可以忽略)
起始标签右边的“>”:
记录char数组的偏移量,取出两次偏移量当中的内容,得到当前标签的标签名。
ZLXMLParser类的processStartTag方法 -> XHTMLReader类的startElementHandler方法 -> XHTMLTagParagraphWithControlAction类的doAtStart方法
结束标签左边的“<”:
记录char数组的偏移量,取出两次偏移量当中的内容,得到标签当中的文本信息
XHTMLReader类的characterDataHandler方法 -> BookReader类的addData方法
将标签当中的文本信息存储到BookReader类的myTextBuffer属性
结束标签右边的“>”:
ZLXMLParser类的processEndTag方法 -> XHTMLReader类的endElementHandler方法 -> 标签名对应XHTMLTagAction接口实现类的doAtEnd方法
将BookReader类中的myTextBuffer属性
下面我们再以《三体1》中的一段文本作为例子来详细介绍下这个流程:

H1标签处理流程
起始标签右边的“<”:
记录char数组的偏移量
起始标签右边的“>”:
记录char数组的偏移量,取出两次偏移量当中的内容,得到当前标签的标签名。
ZLXMLParser类的processStartTag方法 -> XHTMLReader类的startElementHandler方法 -> XHTMLTagParagraphWithControlAction类的doAtStart方法
doAtStart方法
doAtStart方法会调用了两个方法BookReader类的pushKind方法与beginParagraph方法
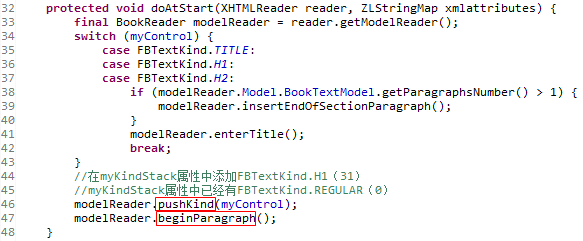
BookReader类的pushKind方法:
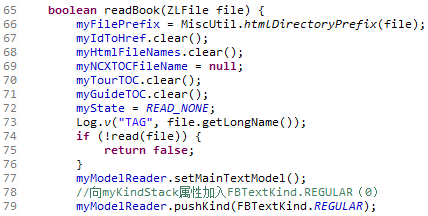
这个方法会在myKindStack属性中添加FBTextKind.H1(31),而其实myKindStack属性中已经有FBTextKind.REGULAR(0),这个属性是在OEBBookReader类的readBook方法中设置的。
BookReader类的beginParagraph方法
这个方法调用了ZLTextWritablePlainModel类的createParagraph方法,然后用for循环迭代myKindStack属性并调用ZLTextWritablePlainModel类的addControl方法
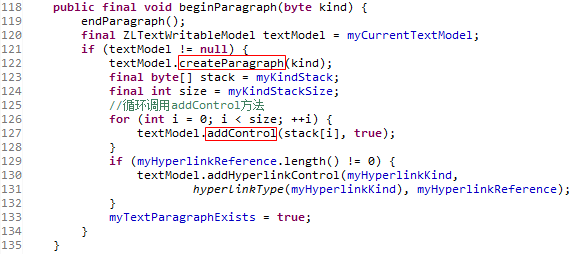
createParagraph方法更新了ZLTextWritablePlainModel类中的三个属性,以后会依靠这三个属性在CachedCharStorage类的char数组中快速定位某一个段落

addControl方法往CachedCharStorage类中的char数组加入了两个可以代表标签的常量

PS:每次调用addControl方法都会加入ZLTextParagraph.Entry.CONTROL(3)这个常量,这个常量是一种标示。类似的标示还有常量ZLTextParagraph.Entry.TEXT(1),我们会在下一章用到这两种变量。具体这两个标示是如何发挥作用的,请参考第十章中的内容。
结束标签左边的“<”:
记录char数组的偏移量,取出两次偏移量当中的内容,得到标签当中的文本信息
XHTMLReader类的characterDataHandler方法,将标签当中的文本信息存储到myTextBuffer属性

结束标签右边的“>”:
ZLXMLParser类的processEndTag方法 -> XHTMLReader类的endElementHandler方法 -> XHTMLTagParagraphWithControlAction类的doAtEnd方法
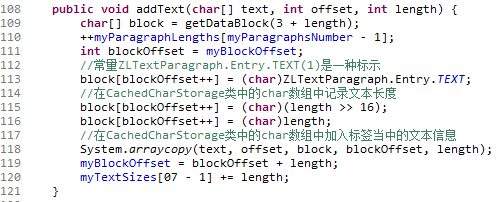
doAtEnd方法会调用ZLTextWritablePlainModel类的addText方法,在CachedCharStorage类中的char数组中加入三种信息:
1、常量ZLTextParagraph.Entry.TEXT(1),这是一种标示,类似常量ZLTextParagraph.Entry.CONTROL(3)
2、标签间文本信息的长度
3、标签间的实际文本信息
H2标签、P标签与H1标签基本上是一样,唯一的区别在于在起始标签右边的“>”触发的addControl方法中加入不同的常量,而这个变量其实是在FBTextKind接口中定义的。
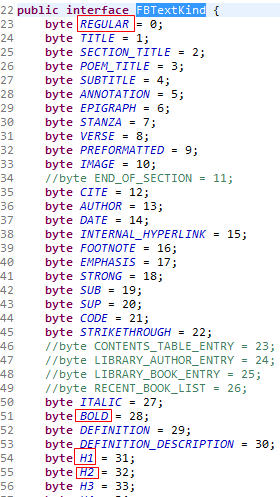
H2标签会加入FBTextKind.REGULAR(0)以及FBTextKind.H2(32),P标签则只会加入FBTextKind.REGULAR(0)。每次加入这些常量的时候都会同时加入作为标示的常量ZLTextParagraph.Entry.TEXT(1)。
B标签与其他三个标签不同,这个标签会触发两次addControl方法,只是两次的参数不同。

CachedCharStorage类中新增char数组
这里需要补充下CachedCharStorage类中新增char数组的流程,我们在介绍CachedCharStorage类的时候,曾经讲过:“BookModel类中的myBlockSize属性指向一个int。char数组的长度最长不会超过这个int(65536),一旦超过这个长度,代码就会新建一个char数组,同时就的数组会被持久化以便以后再用。”
新增char数组的工作由CachedCharStorage的createNewBlock方法完成

将旧的char数组持久化的工作是在CachedCharStorage类的freezeLastBlock方法完成的。
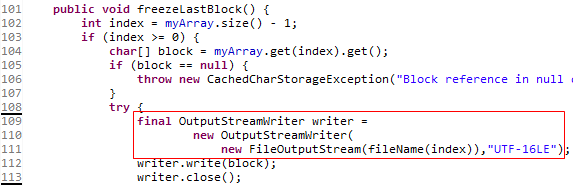
在sd卡上的Books/.FBReader这个文件夹里面,我们可以找到这些持久化了的文件。

这个位置是在BookModel的构建函数中用过Paths类获得的。


其实我们可以尝试把持久化char数组的方法改为utf8的编码,然后在把得到的文件后缀名改成.txt
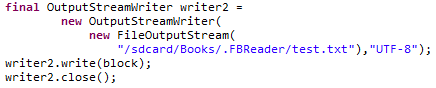
打开这个txt文件,我们就可以看到下面这样的数据

对比原先的xml文件,那些奇怪的符号就代表了标签信息

好,至此为止,我们将.xhtml文件中的文本信息与标签信息存储到了ZLTextPlainModel中。而要想让程序最终用中正确的格式显示文本信息,还需要配合之后第八章(定位指定段落)以及第九章(显示.html文件)的内容才能让用户看到格式正确的文本。
题外话
最后,插几句题外话,写一些自己的思考:
FBReader使用char数组的形式来存储xml文件内容与结构信息,然后依靠记录每个段落在char数组中具体位置的int数组快速获取指定段落在char数组中的部分。选择数组是ok的,在数组中定位到某一个部分,速度还是比较快的,但是同时,也因为使用了数组这个数据结构,程序也是相对来说比较占用内存的。一般来说,电子书都是从一整段数据中按顺序取出一部分数据显示在屏幕上,这种业务需求其实用树的数据结构也是非常合适的。而说到树的数据结构,其实Android手机中正好有一个现成的sqlite数据库可以提供这种树的数据结构。我们可以试想一下,如果改用sqlite数据库来存储和检索xml文件的内容与结构信息的话,相比数组会有怎样的好处。我想最起码会有三个好处:第一、节省手机的内存,sqlite数据库做好索引之后,无需像数组那样把数据全部装进内存后才能检索。这样一来,程序就节省了内存;二、方便跨平台的开发,sqlite支持linux、IOS以及HTML5,如果使用sqlite来作为存储和检索xml文件的方式,那么Android程序员、IOS程序员以及pc前端程序员只需要根据约定的sql语句就能完成开发,而不必独立开发三种语言,或者用c或c++另外再开发一个底层库;三、方便与服务器端对接,当需要对客户端用户的阅读记录进行收集与分析的时候,如果客户端与服务端使用同一种或相近的sql结构的话,那么对接的难度就会降低很多。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































