
Twitter网站架构介绍
一、twitter网站基本情况概览
截至2011年4月,twitter的注册用户约为1.75亿,并以每天300000的新用户注册数增长,但是其真正的活跃用户远远小于这个数目,大部分注册用户都是没有关注者或没有关注别人的,这也是与facebook的6亿活跃用户不能相提并论的。
twitter每月有180万独立访问用户数,并且75%的流量来自twitter.com以外的网站。每天通过API有30亿次请求,每天平均产生5500次tweet,37%活跃用户为手机用户,约60%的tweet来自第三方的应用。
平台:Ruby on Rails 、Erlang 、MySQL 、Mongrel 、Munin 、Nagios 、Google Analytics 、AWStats 、Memcached
下图是twitter的整体架构设计图: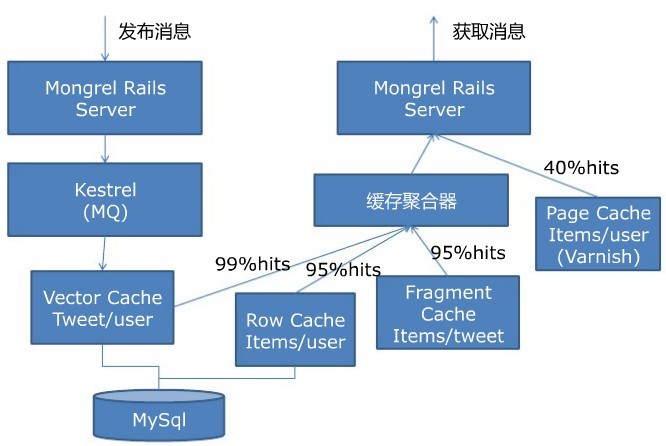
二、twitter的平台
twitter平台大致由twitter.com、手机以及第三方应用构成,如下图所示: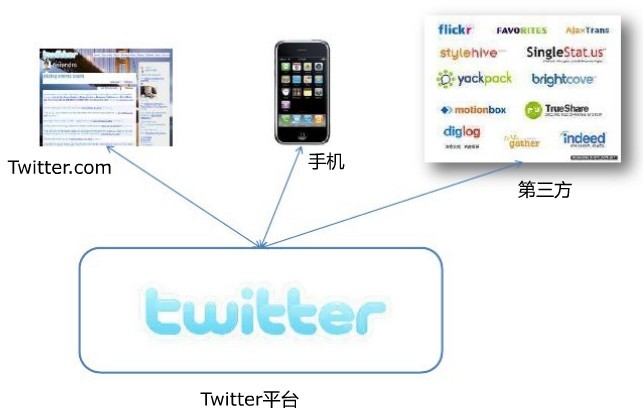
其中流量主要以手机和第三方为主要来源。
Ruby on Rails:web应用程序的框架
Erlang:通用的面向并发的编程语言,开源项目地址:http://www.erlang.org/
AWStats:实时日志分析系统:开源项目地址:http://awstats.sourceforge.net/
Memcached:分布式内存缓存组建
Starling:Ruby开发的轻量级消息队列
Varnish:高性能开源HTTP加速器
Kestrel:scala编写的消息中间件,开源项目地址:http://github.com/robey/kestrel
Comet Server:Comet是一种ajax长连接技术,利用Comet可以实现服务器主动向web浏览器推送数据,从而避免客户端的轮询带来的性能损失。
libmemcached:一个memcached客户端
使用mysql数据库服务器
Mongrel:Ruby的http服务器,专门应用于rails,开源项目地址:http://rubyforge.org/projects/mongrel/
Munin:服务端监控程序,项目地址:http://munin-monitoring.org/
Nagios:网络监控系统,项目地址:http://www.nagios.org/
三、缓存
讲着讲着就又说到缓存了,确实,缓存在大型web项目中起到了举足轻重的作用,毕竟数据越靠近CPU存取速度越快。下图是twitter的缓存架构图: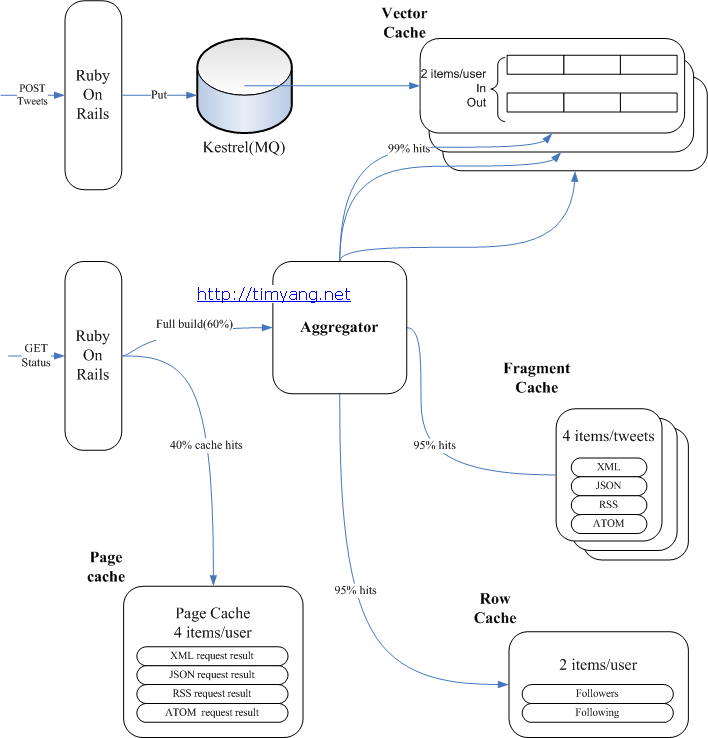
大量使用memcached作缓存
例如,如果获得一个count非常慢,你可以将count在1毫秒内扔入memcached
获取朋友的状态是很复杂的,这有安全等其他问题,所以朋友的状态更新后扔在缓存里而不是做一个查询。不会接触到数据库
ActiveRecord对象很大所以没有被缓存。Twitter将critical的属性存储在一个哈希里并且当访问时迟加载
90%的请求为API请求。所以在前端不做任何page和fragment缓存。页面非常时间敏感所以效率不高,但Twitter缓存了API请求
在memcached缓存策略中,又有所改进,如下所述:
1、创建一个直写式向量缓存Vector Cache,包含了一个tweet ID的数组,tweet ID是序列化的64位整数,命中率是99%
2、加入一个直写式行缓存Row Cache,它包含了数据库记录:用户和tweets。这一缓存有着95%的命中率。
3、引入了一个直读式的碎片缓存Fragmeng Cache,它包含了通过API客户端访问到的sweets序列化版本,这些sweets可以被打包成json、xml或者Atom格式,同样也有着95%的命中率。
4、为页面缓存创建一个单独的缓存池Page Cache。该页面缓存池使用了一个分代的键模式,而不是直接的实效。
四、消息队列
大量使用消息。生产者生产消息并放入队列,然后分发给消费者。Twitter主要的功能是作为不同形式(SMS,Web,IM等等)之间的消息桥
使用DRb,这意味着分布式Ruby。有一个库允许你通过TCP/IP从远程Ruby对象发送和接收消息,但是它有点脆弱
移到Rinda,它是使用tuplespace模型的一个分享队列,但是队列是持久的,当失败时消息会丢失
尝试了Erlang
移到Starling,用Ruby写的一个分布式队列
分布式队列通过将它们写入硬盘用来挽救系统崩溃。其他大型网站也使用这种简单的方式
五、总结
1、数据库一定要进行合理索引
2、要尽可能快的认知你的系统,这就要你能灵活地运用各种工具了
3、缓存,缓存,还是缓存,缓存一切可以缓存的,让你的应用飞起来。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































