
【转帖】【面向代码】学习 Deep Learning(四) Stacked Auto-Encoders(SAE)
今天介绍的呢是DL另一个非常重要的模型:SAE
把这个放在最后来说呢,主要是因为在UFLDL tutorial 里已经介绍得比较详细了,二来代码非常简单(在NN的基础之上)
先放一张autoencoder的基本结构:
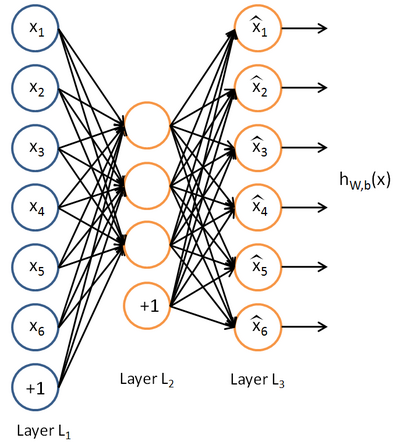
基本意思就是一个隐藏层的神经网络,输入输出都是x,属于无监督学习
==========================================================================================
基本代码
saesetup.m
- function sae = saesetup(size)
- for u = 2 : numel(size)
- sae.ae{u-1} = nnsetup([size(u-1) size(u) size(u-1)]);
- end
- end
function sae = saesetup(size)
for u = 2 : numel(size)
sae.ae{u-1} = nnsetup([size(u-1) size(u) size(u-1)]);
end
end
saetrain.m
- function sae = saetrain(sae, x, opts)
- for i = 1 : numel(sae.ae);
- disp([‘Training AE ‘ num2str(i) ‘/‘ num2str(numel(sae.ae))]);
- sae.ae{i} = nntrain(sae.ae{i}, x, x, opts);
- t = nnff(sae.ae{i}, x, x);
- x = t.a{2};
- %remove bias term
- x = x(:,2:end);
- end
- end
function sae = saetrain(sae, x, opts)
for i = 1 : numel(sae.ae);
disp([‘Training AE ‘ num2str(i) ‘/‘ num2str(numel(sae.ae))]);
sae.ae{i} = nntrain(sae.ae{i}, x, x, opts);
t = nnff(sae.ae{i}, x, x);
x = t.a{2};
%remove bias term
x = x(:,2:end);
end
end
其实就是每一层一个autoencoder,隐藏层的值作为下一层的输入
各类变形
为了不致于本文内容太少。。。现在单独把它的几个变形提出来说说
sparse autoencoder:
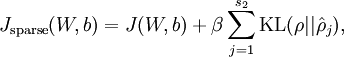
这就是ufldl讲的版本,toolbox中的代码和ufldl中练习的部分基本一致:
在nnff.m中使用:nn.p{i} = 0.99 * nn.p{i} + 0.01 * mean(nn.a{i}, 1);计算
在nnbp.m中使用
pi = repmat(nn.p{i}, size(nn.a{i}, 1), 1);
sparsityError = [zeros(size(nn.a{i},1),1) nn.nonSparsityPenalty * (-nn.sparsityTarget ./ pi + (1 - nn.sparsityTarget) ./ (1 - pi))];
计算sparsityError即可
denoising autoencoder:
denoising其实就是在autoencoder的基础上,给输入的x加入噪声,就相当于dropout用在输入层
toolbox中的也实现非常简单:
在nntrain.m中:
batch_x = batch_x.*(rand(size(batch_x))>nn.inputZeroMaskedFraction)
也就是随即把大小为(nn.inputZeroMaskedFraction)的一部分x赋成0,denoising autoencoder的表现好像比sparse autoencoder要强一些
Contractive Auto-Encoders:
这个变形呢是《Contractive auto-encoders: Explicit invariance during feature extraction》提出的
这篇论文里也总结了一下autoencoder,感觉很不错
Contractive autoencoders的模型是:

其中:

论文里说:这个项是
encourages the mapping to the feature space to be contractive in the neighborhood of the training data
具体的实现呢是:

代码呢参看:论文作者提供的:点击打开链接
主要是
jacobian(self,x):
_jacobi_loss():
_fit_reconstruction():
这几个函数和autoencoder有出入,其实也比较简单,就不细讲了
总结:
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































