
BaseHTTPServer与CGIHTTPServer学习札记
今天学习了《Python核心编程》中Web服务器相关章节。于是走读了一下python的源码。
本人电脑上安装的是python2.6,相应的源码文件存放在 /usr/lib/python2.6/ 路径下。
1 BaseHTTPServer浅析
打开 /usr/lib/python2.6/BaseHTTPServer.py 文件。
1.1 HTTPServer类
最上面定义了类 HTTPServer,继承于 SocketServer.TCPServer,它不断接收数据,并将接收到的数据交给 RequestHandler 处理。
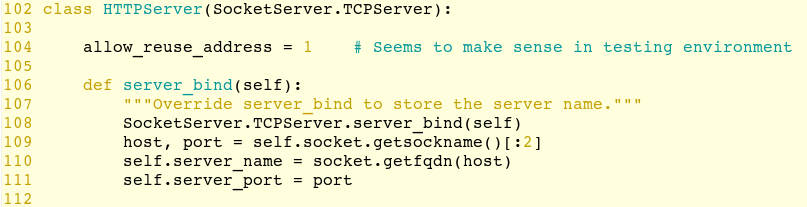
它没有在TCPServer的基础上添加大量的功能,只加了一个server_bind()成员函数。
1.2 BaseHTTPRequestHandler类
看到类 BaseHTTPRequestHandler,这个类负责处理接收到的HTTP请求,如POST,GET之类的。
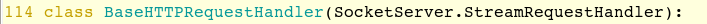
看到它的成员函数 handle()

请求处理就是调用handle()函数进行的。首先,它将类成员变量close_connection置为1,如果在handle_one_request()执行中没有将其置为0,那么handle()就返回了。
那在什么情况下close_connection会被置为0呢?如果请求的header里有 Connection:keep-alive时会被清0。见parse_request()中:

从上面的while循环可以看到,如果close_connection为0,那么就继续执行handle_one_request(),直到close_connection为1为至。
那么 handle_one_request() 又在干什么呢?顾名思义,就是处理一个请求。

L312:从rfile读取请求的数据,也就是HTTP报文数据。
L313~L315:如果读失败退出。
L316~L317:调用parse_request()对HTTP报文header进行解析,如果失败则退出。
L318:根据command,生成处理函数名,如GET命令生成的是do_GET。
L319~L323:检查当前类是否有 do_XXX() 成员函数,如果存在 do_XXX() 这个成员函数。
再看一下 parse_request() 是如何分析HTTP header的。主要分两步:
(1)读对报文数据的第一行,格式是:<命名> <路径> <HTTP版本>,通常是:“GET / HTTP/1.1”。
分析版号是否正确,并解析出command, path, version,并保存到对应的成员变量中。
(2)检查headers是中的Connection,如果是keep-alive,那么就得将close_connection置为0,以保存连接。
从对BaseHTTPRequestHandler的分析可以得知,如果我们要响应POST,GET命令,那必须得继承于BaseHTTPRequestHandler,并定义好do_GET()与do_POST()函数。
除了上述的三个重要的函数外,BaseHTTPRequestHandler 还提供了很多有用的成员函数:
send_error(code, message=None)
send_respond(code, message=None)
send_header(keyword, value)
end_headers()
...
2 CGIHTTPServer浅析
打开 /usr/lib/python2.6/CGIHTTPServer.py 文件。文件里只定义了一个 CGIHTTPRequestHandler 类,继承于 SimpleHTTPServerHandler。
其实 SimpleHTTPRequestHandler 是继承于 BaseHTTPRequestHandler 的。

它实现了 do_POST() 函数:

意思很简单,如果是CGI,那么就执行CGI,否则报错。
那怎么才算是CGI呢?我们跟踪一下 is_cgi() 函数:

看起来很简单,也就是在目录 cgi_directories 下的文件,认为是cgi文件。在L89定义了 cgi_directories,也就是在 /cgi-bin 或 /htbin 目录下的都认为是 cgi。
_url_collapse_path_split(path) 函数是用于规整路径的,防止路径中出现过多 ./ 或 .. / 出现的防问漏洞。
那么怎么执行cgi的呢?我们一起跟一下 run_cgi() 函数。
待续……
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































