
Scala与Golang的并发实现对比
并发语言俨然是应大规模应用架构的需要而提出,有其现实所需。前后了解了Scala和Golang,深深体会到现代并发语言与旧有的Java、C++等语言在风格及理念上的巨大差异。本文主要针对Scala和Golang这两个我喜爱的并发语言在并发特性上的不同实现,做个比较和阐述,以进一步加深理解。
一. Scala与Golang的并发实现思路
Scala语言并发设计采用Actor模型,借鉴了Erlang的Actor实现,并且在Scala 2.10之后,Scala采用的是Akka Actor模型库。Actor模型主要特征如下:
- “一切皆是参与者”,且各个actor间是独立的;
- 发送者与已发送消息间解耦,这是Actor模型显著特点,据此实现异步通信;
- actor是封装状态和行为的对象,通过消息交换进行相互通信,交换的消息存放在接收方的邮箱中;
- actor可以有父子关系,父actor可以监管子actor,子actor唯一的监管者就是父actor;
- 一个actor就是一个容器,它包含了状态、行为、一个邮箱(邮箱用来接受消息)、子actor和一个监管策略;
- goroutine(协程,Go的轻量级线程)是Go的轻量级线程管理机制,用“go”启动一个goroutine, 如果当前线程阻塞则分配一个空闲线程,如果没有空闲线程,则新建一个线程;
- 通过管道(channel)来存放消息,channel在goroutine之间传递消息;比如通过读取channel里的消息(通俗点说好比一个个“值”),你能够明白某个goroutine里的任务完成以否;
- Go给channel做了增强,可带缓存。
- actor是异步的,因为发送者与已发送消息间实现了解耦;而channel则是某种意义上的同步,比如channel的读写是有关系的,期间会依赖对方来决定是否阻塞自己;
- actor是一个容器,使用actorOf来创建Actor实例时,也就意味着需指定具体Actor实例,即指定哪个actor在执行任务,该actor必然要有“身份”标识,否则怎么指定呢?!而channel通常是匿名的, 任务放进channel之后你不用关心是哪个channel在执行任务;
我们来看一个例子:对一组连续序列(1-10000)的整数值进行累加,分别观察Scala与Go环境下单线程与多线程效率,一方面了解并发效率的提升;一方面也能够对比Scala与Go并发实现的差异 ── 这才是本文的重点。具体要求如下:
对1 - 10000的整数进行累加,在并发条件下,我们将1 - 10000平均划分为四部分,启动四个线程进行并发计算,之后将四个线程的运行结果相加得出最终的累加统计值。为了更明显地观察到时间上的差异性,在每部分的每次计算过程中,我们添加一个3000000次的空循环:)
三. Scala实现
以下先列出Scala Akka Actor并发实现的完整示例代码:
// Akka并发计算实例
import akka.actor.Actor
import akka.actor.Props
import akka.actor.ActorSystem
import akka.routing.RoundRobinPool
// 定义一个case类
sealed trait SumTrait
case class Result(value: Int) extends SumTrait
// 计算用的Actor
class SumActor extends Actor {
val RANGE = 10000
def calculate(start: Int, end: Int, flag : String): Int = {
var cal = 0
for (i <- (start to end)) {
for (j <- 1 to 3000000) {}
cal += i
}
println("flag : " + flag + ".")
return cal
}
def receive = {
case value: Int =>
sender ! Result(calculate((RANGE / 4) * (value - 1) + 1, (RANGE / 4) * value, value.toString))
case _ => println("未知 in SumActor...")
}
}
// 打印结果用的Actor
class PrintActor extends Actor {
def receive = {
case (sum: Int, startTime: Long) =>
println("总数为:" + sum + ";所花时间为:"
+ (System.nanoTime() - startTime)/1000000000.0 + "秒。")
case _ => println("未知 in PrintActor...")
}
}
// 主actor,发送计算指令给SumActor,发送打印指令给PrintActor
class MasterActor extends Actor {
var sum = 0
var count = 0
var startTime: Long = 0
// 声明Actor实例,nrOfInstances是pool里所启routee(SumActor)的数量,
// 这里用4个SumActor来同时计算,很Powerful。
val sumActor = context.actorOf(Props[SumActor]
.withRouter(RoundRobinPool(nrOfInstances = 4)), name = "sumActor")
val printActor = context.actorOf(Props[PrintActor], name = "printActor")
def receive = {
case "calculate..." =>
startTime = System.nanoTime()
for (i <- 1 to 4) sumActor ! i
case Result(value) =>
sum += value
count += 1
if (count == 4) {
printActor ! (sum, startTime)
context.stop(self)
}
case _ => println("未知 in MasterActor...")
}
}
object Sum {
def main(args: Array[String]): Unit = {
var sum = 0
val system = ActorSystem("MasterActorSystem")
val masterActor = system.actorOf(Props[MasterActor], name = "masterActor")
masterActor ! "calculate..."
Thread.sleep(5000)
system.shutdown()
}
}
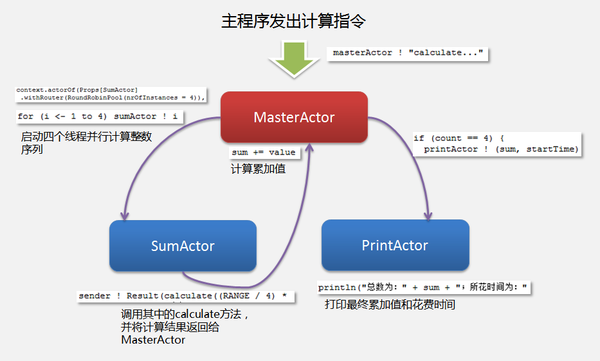 在这里,我们一共定义了 三个Actor实例(actor),MasterActor、SumActor和PrintActor,其中,前者是后两者的父亲actor,如前文Scala的Actor模型特征里提到的:“actor可以有父子关系,父actor可以监管子actor,子actor唯一的监管者就是父actor”。
在这里,我们一共定义了 三个Actor实例(actor),MasterActor、SumActor和PrintActor,其中,前者是后两者的父亲actor,如前文Scala的Actor模型特征里提到的:“actor可以有父子关系,父actor可以监管子actor,子actor唯一的监管者就是父actor”。我们的主程序通过向MasterActor发送“calculate...”指令,启动整个计算过程,嗯哼,好戏开始登场了:)
注意以下代码:
val sumActor = context.actorOf(Props[SumActor]
.withRouter(RoundRobinPool(nrOfInstances = 4)), name = "sumActor")
这里的设置将会在线程池里初始化称为“routee”的子actor(这里是SumActor),数量为4,也就是我们需要4个SumActor实例参与并发计算。这一步很关键。
然后,在接受消息的模式匹配中,通过以下代码启动计算actor:
for (i <- 1 to 4) sumActor ! i
在SumActor中,每个计算线程都会调用calculate方法,该方法将处理分段的整数累加,并返回分段累加值给父actor MasterActor,我们特地通过case类实现MasterActor接受消息中的一个模式匹配功能(case Result(value) =>...),可以发现,模式匹配在Scala并发功能实现中的地位非常重要,并大大提升了开发人员的开发效率。在这里,我们获取了4个并发过程返回的分段累加值,MasterActor会计算最终的累加值。如果4个并发过程全部完成,就调用PrintActor实例打印结果和所花时间。
在整个运算过程中,我们很容易理解发送者与已发送消息间的解耦特征,发送者和接受者各种关心自己要处理的任务即可,比如状态和行为处理、发送的时机与内容、接收消息的时机与内容等。当然,actor确实是一个“容器”,且“五脏俱全”:我们用类来封装,里面也封装了必须的逻辑方法。
Scala Akka的并发实现,给我的感觉是设计才是关键,将各个actor的功能及关联关系表述清楚,剩余的代码实现就非常容易,这正是Scala、Akka的魅力体现,在底层帮我们做了大量工作!
在这里的PrintActor实际上并无太大存在意义,因为它并不实现并发功能。实现它主要是为了演示actor间的消息传递与控制。
再来看看单线程的计算运行模式:
...
val RANGE = 10000
var cal = 0
val startTime = System.nanoTime()
for (i <- (1 to RANGE)) {
for (j <- 1 to 3000000) {}
cal += i
}
val endTime = System.nanoTime()
...
四. Go语言实现
仍然先列出Go语言实现的并发功能完整代码:
// Go并发计算实例
package main
import (
"fmt"
"runtime"
"strconv"
"time"
)
type Sum []int
func (s Sum) Calculate(count, start, end int, flag string, ch chan int) {
cal := 0
for i := start; i <= end; i++ {
for j := 1; j <= 3000000; j++ {
}
cal += i
}
s[count] = cal
fmt.Println("flag :", flag, ".")
ch <- count
}
func (s Sum) LetsGo() {
// runtime.NumCPU()可以获取CPU核数,我的环境为4核,所以这里就简单起见直接设为4了
const NCPU = 4
const RANGE = 10000
var ch = make(chan int)
runtime.GOMAXPROCS(NCPU)
for i := 0; i < NCPU; i++ {
go s.Calculate(i, (RANGE/NCPU)*i+1, (RANGE/NCPU)*(i+1), strconv.Itoa(i+1), ch)
}
for i := 0; i < NCPU; i++ {
<-ch
}
}
func main() {
var s Sum = make([]int, 4, 4)
var sum int = 0
var startTime = time.Now()
s.LetsGo()
for _, v := range s {
sum += v
}
fmt.Println("总数为:", sum, ";所花时间为:",
(time.Now().Sub(startTime)), "秒。")
}
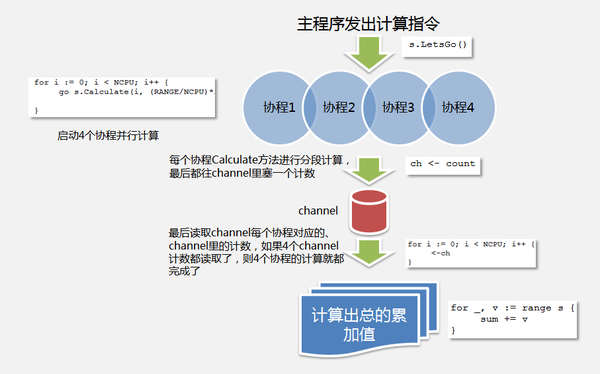 由上可知,Go语言的并发魔力来源于goroutine和channel。我们定义了一个Sum类型(插一句:Go语言的类型系统设计得也非常特别,这是别的主题了,:)),它有两个方法:LetsGo()和Calculate,LetsGo()首先创建一个计数用的channel,随后发起4个并发计算的协程。每个计算协程调用Calculate()进行分段计算(并会传入channel),Calculate()方法的最后,在分段计算完成时,都会往channel里塞一个计数标志:
由上可知,Go语言的并发魔力来源于goroutine和channel。我们定义了一个Sum类型(插一句:Go语言的类型系统设计得也非常特别,这是别的主题了,:)),它有两个方法:LetsGo()和Calculate,LetsGo()首先创建一个计数用的channel,随后发起4个并发计算的协程。每个计算协程调用Calculate()进行分段计算(并会传入channel),Calculate()方法的最后,在分段计算完成时,都会往channel里塞一个计数标志:ch <- count
for i := 0; i < NCPU; i++ {
<-ch
}
对于channel的写入、等待和读取,简单形象地用下图描述:
 这里为了演示方便,且本例中的协程和业务逻辑也不至于会造成协程僵死或locked,因此未考虑协程永久等待的处理,如果要处理超时,可以这么考虑:
这里为了演示方便,且本例中的协程和业务逻辑也不至于会造成协程僵死或locked,因此未考虑协程永久等待的处理,如果要处理超时,可以这么考虑:
for {
select {
case <-ch: ...
case <-time.After(3 * time.Second): ...
}
}
select机制也是Go语言并发处理中的强大武器,由于与本主题关系不大,故不表。但可以看出,Go语言有Unix和C的深深烙印,select、channel概念就是很好的例证。
在所有的分段计算结束后,就可以计算总的累加值了:
for _, v := range s {
sum += v
}
这段代码从Sum类型实例中获取分段累加值,最后计算出总的累加统计值。
Go中的channel是可以带缓存的,在缓存未被填满之前,都可以写入。本例中未使用带缓存的channel,虽然这样做在理论上可以节省写入channel时的等待时间,但在这里可以忽略,大型应用中就要慎重对待了。
来看看单线程的计算运行模式:
...
cal := 0
for i := start; i <= end; i++ {
for j := 1; j <= 3000000; j++ {
}
cal += i
}
...
运行效率
先来看看运行效率。我的操作系统是Windows 8.1 64位,分别用以下命令编译及运行Scala和Go程序并发程序:
scalac -cp lib\akka-actor_2.11-2.3.4.jar Sum.scala
scala Sum
go build Sum.go
Sum
Scala:7.189461763秒(单线程模式),3.895642655秒(并发模式)
Golang 12.987232秒(单线程模式),7.1636263秒(并发模式)
从上可知,Scala与Go语言的并发实现都比单线程实现快了45%左右,这个数据还是比较可观的。而Golang并发却比Scala并发慢了不少,事实的确如此吗?我在另一台比较旧的32位操作系统机器上运行,Scala的并发足足花了近300秒,而Go语言并发差不多是20秒。因此,拿Scala和Go的并发效率来对比,应该是没什么意义的,其间要受到各自内部实现、类型系统、内存使用机制、并发模式、并发规模以及硬件支持等等复杂因素的影响。如果一定要对两者进行比较,则肯定会引发口水战。
模式上的差异
如果前面讲述“Scala与Golang的并发实现思路”时,理解起来还比较抽象,但经过上面的示例说明与比较,相信感知会比较具体了:
- Akka的actor是解耦的、相对独立的,定义好各个actor间如何沟通,剩下的东西就尽管交给它们处理好了,它们自会按既定方式各司其职,而且每个actor“麻雀虽小五脏俱全”,这也是其解耦性做得好的必然基础。Go语言则独辟蹊径,通过“go”魔法和Unix风格的channel,以更轻量级的协程方式来处理并发,虽说是更轻量,但你仍得花点心思关注下channel的状态,别一不小心阻塞了,特别是channel多了、复杂了,并且其中包含了业务处理所需数据、而不仅仅只是计数标志的情况下;
- Akka的Actor实现是库的形式,其也能应用于Java语言。Go语言内嵌了协程的并发实现;
- Akka基于JVM,实现模式是面向对象,天然讲究抽象与封装,虽然可以穿插混合应用函数式风格。而Go语言显然体现了命令式语言的风格,在需要考虑封装性的时候,需要开发者多着墨。
是Scala还是Go?
据说Go语言中轻量级的协程可以轻易启动数十上百万个,这对Scala来说当然是有压力的。但相较而言,Go语言的普及及应用程度尚远不及Java生态,我也希望更多的应用能够实践Go语言。此外,从代码简洁程度来看,Go语言应该会更简洁些吧。
在你了解了Akka之后,再回过头来看看Java与它的concurrent,就会有一种弱爆了的感觉,动不动就阻塞、同步。因此,如果是Java平台上的选择,不要说Akka就是很重要的考量指标了。
不得不提的一点是,不同模式有其适用的业务和环境,因此,选择Scala还是Go语言来实现功能,这必须有赖于现实业务与环境的需求──是Scala还是Go?这永远是个问题。
六. 结束语
并发实现及场景是复杂的,比如远程调用、异常处理以及选择恰当的并发模式等。需要不断深入学习与实践,才能对并发技能运用自如。希望通过本文的阐述,能够让你了解到一些Scala与Golang的并发实现思路。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。

































