
mysql分区技术
当 MySQL中一个表的总记录数超过了1000万后,会出现性能的大幅度下降吗?答案是肯定的,但是性能下降的比率不一而同,要看系统的架构、应用程序,甚至还要根据索引、服务器硬件等多种因素而定。比如FCDB和SFDB中的关键词,多达上亿的数据量,分表之后的单个表也已经突破千万的数据量,导致单个表的更新等均影响着系统的运行效率。甚至是一条简单的SQL都有可能压垮整个数据库,如整个表对某个字段的排序操作等。目前,针对海量数据的优化主要有2中方法:大表拆小表的方式和SQL语句的优化。SQL语句的优化可以通过增加索引等来调整,但是数据量的增大将会导致索引的维护代价增大。在此不详述,建议大家参考相应的High Performance MySQL等书籍。另外,大表拆小表的方式主要有两种:
垂直分表:

图1. 垂直分区示意图
对于垂直分表,它将一个N1+N2个字段的表Tab拆分成N1字段的子表Tab1和(N2+1)字段的子表Tab2;其中子表Tab2包含了关于子表Tab1的主键信息,否则两个表的关联关系就会丢失。当然垂直分表会带来程序端SQL的修改,若是应用程序已经应用很长的一段时间,然后程序的升级将是耗时而且易出错的,即升级的代价将会很大。
水平分表:

图2. 水平分区示意图
水平分区技术将一个表拆成多个表,比较常用的方式是将表中的记录按照某种Hash算法进行拆分,简单的拆分方法如取模方式。同样,这种分区方法也必须对前端的应用程序中的SQL进行修改方可使用。而且对于一个SQL,它可能会修改两个表,那么你必须得写成2个SQL语句从而可以完成一个逻辑的事务,使得程序的判断逻辑越来越复杂,这样也会导致程序的维护代价高,也就失去了采用数据库的优势。因此,分区技术可以有力地避免如上的弊端,成为解决海量数据存储的有力方法。2. MySQL分区介绍
MySQL的分区技术不同与之前的分表技术,它与水平分表有点类似,但是它是在逻辑层进行的水平分表,对与应用程序而言它还是一张表。
2.1 MySQL分区类型
MySQL5.1有5中分区类型:
RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区;
LIST 分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择;
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
KEY 分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。
2.2 RANGE分区
对于RANGE分区,举个例子:
例1. 假定你创建了一个如下的一个表,该表保存有20家音像店的职员记录,这20家音像店的编号从1到20。 如果你想将其分成4个小分区,那么你可以采用RANGE分区,创建的数据库表如下:

这个例子,它的key是一个整型的数据,那是否对于其它类型的字段就无法作为key呢? 答案是否定的,例子2说明这种情况。
例2. 假定你创建了一个如下的一个表,该表保存有20家音像店的职员记录,这20家音像店的编号从1到20。你想把不同时期离职的员工进行分别存储,那么你可以将日期字段separated(即离职时间)作为一个key,创建的SQL语句如下:

这样你就可以对一个日期类型的字段调用mysql的日期函数YEAR()转换为一种整数类型,从而可以作为RANGE分区的key。这个时候,你可以看到,按照分区后的物理文件是相对独立的:

可知,每个分区有自己独立的数据文件和索引文件,这是为什么你对某一个查询,它只会访问它需要访问的数据块,而不访问根本不是结果的物理块,从而可以大大提高系统的效率。2.3 LIST分区
LIST分区与RANGE分区有类似的地方,举个与例1类似的例子如下:
例3. 假定你创建了一个如下的一个表,该表保存有20家音像店的职员记录,这20家音像店的编号从1到20。 而这20个音像店,分布在4个有经销权的地区,如下表所示:
地区 商店ID 号
北区 3, 5, 6, 9, 17
东区 1, 2, 10, 11, 19, 20
西区 4, 12, 13, 14, 18
中心区 7, 8, 15, 16
那么你可以采用如下的LIST分区语句创建数据表:

同样,它在物理文件上也会标识不同的分区:

2.4 HASH分区
HASH分区主要用来确保数据在预先确定数目的分区中平均分布。它可以基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。
例4. 假定你创建了一个如下的一个表,该表保存有20家音像店的职员记录,这20家音像店的编号从1到20。你想把不同时期加入的员工进行分别存储,那么你可以将日期字段hired(即离职时间)作为一个key,创建的SQL语句如下:

那么要插入一个‘2005-09-15’入职的员工E1,那么按照取模函数会将其放置到第2分区中:
MOD(YEAR(‘2005-09-01’), 4)= MOD(2005,4)= 1 //即第2分区
2.5 KEY分区
与HASH分区类似,但它的key可以不是整数类型,如字符串等类型的字段。MySQL 簇(Cluster)使用函数MD5()来实现KEY分区;对于使用其他存储引擎的表,服务器使用其自己内部的哈希函数,这些函数是基于与 PASSWORD()一样的运算法则。2.6 不同分区技术的对比
如上分别列出了不同的分区技术,接下来进行对比,如下表所示:
分区类型 优点 缺点 共性
Range 适合与日期类型,支持复合分区 有限的分区 一般只针对某一列
List 适合与有固定取值的列,支持复合分区 有限的分区,插入记录在这一列的值不值List中,则数据丢失 一般只针对某一列
Hash 线性Hash使得增加、删除和合并分区更快捷 线性Hash的数据分布不均匀,而一般Hash的数据分布较均匀 一般只针对某一列
Key 列可以为字符型等其它非Int类型 效率较之前的低,因为函数为复杂的函数(如. MD5或SHA函数) 一般只针对某一列
3. 案例分析
这个案例是针对有个员工、部门、部门经理、头衔和销售记录的模拟数据,其ER图如下所示,数据量大概有4百万左右。数据下载URL: https://launchpad.net/test-db


通过如上可知,对于同样的数据按照分区和不分区的技术分别存储,从而便于如下的查询性能分析和对比。 对于salaries表,它采用RANGE分区,定义如下:

3.1 单表查询
从销售记录中找到1999年整年的销售记录有多少条,这个很简单,查询语句如下:
select count(*) from salaries s where s.from_date between "1999-01-01" and "1999-12-31" ;
那么对于分区前后的查询性能却有很大的差别:

通过如上可知,利用分区之后它只需扫描p16分区,访问的记录明显减少,所以性能自然有较大的提升:

无采用分区技术 采用分区技术
3.2 单表查询-BAD Case
若现在有如下查询:
select count(*) from salaries s where year(s.from_date)=1999;
那么它是否能够利用到分区技术呢,答案是否定的。为什么呢,因为分区中的key是s.from_date,而不是 year(s.from_date),mysql并不能很智能地判断year是1999的,那么它就是分为p16分区,这个可以通过如下的查询计划可以证 实:
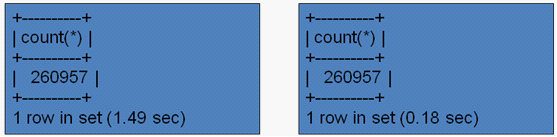
也就是其实它访问了所有的分区,所以并没有很好地利用分区功能,将SQL改写如下:
select count(*) from salaries s where year between ‘1999-01-01‘ and ‘1999-12-31‘ ;
则查询计划如下:

可知,书写正确的SQL可以完全表现出两种相差特别大的性能。
3.3 连接查询
同样地,对于连接查询,在有没有分区的条件下,将有性能3倍左右的差距。对于更大的数据量,可能会有更大的性能差距。SQL如下:
select count(*) from salaries s left join employees e on s.emp_no=e.emp_no where s.from_date between ‘1999-01-01‘ and ‘1999-12-31‘ ;
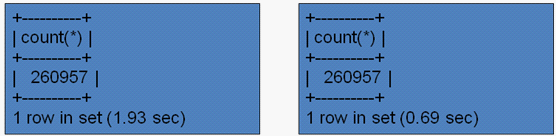
无采用分区 采用分区
3.4 删除查询
为了删除1998年的销售数据,那么在有分区情况下可以不利用delete查询快速地完成垃圾数据的清理。

可知,对于有分区的情况下,只需要将某个分区删除掉即可,时间仅为0.05s,相对应原来的2.82s,这个提升是非常高的。 当然,利用分区功能的数据删除之后,数据文件如下:

那么接下来如果接着插入1998年的数据,数据是否丢失了呢?还是会写不进去?答案也都是否定,它会将数据写入p16分区中。有兴趣的读者可以自己收到试试。
4. 总结和不足
所以,分区的好处有很多:
1. 与单个磁盘或文件系统分区相比,可以存储更多的数据
2. 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。
3. 一些查询可以得到极大的优化,如where语句数据可以只保存在一个或多个分区内
4. 涉及到例如SUM() 和 COUNT()这样聚合函数的查询,可以很容易地进行并行处理
5. 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
在设计分区过程中,需要考虑的因素有很多,如:
– 分区的列
– 分区使用的函数,特别为非Integer类型的列
– 服务器性能
– 内存大小
根据分区技术,有一些技巧:
– 若索引的大小 > RAM,考虑选用分区,不采用索引
– 尽量不采用Primary Key做分区的key
– 当CPU性能高的时候,考虑使用Archive存储引擎
– 对于大量的历史数据,考虑使用Archive+PARTITION
–总之,
MySQL分区技术是一种逻辑的水平分表技术;
它只访问需要访问的分区,从而提高性能;
支持range, hash, key, list和复合分区方法;
支持MySQL服务器所支持的任何存储引擎;
除了Key分区方法,Partition的key 必须是整数(或者能转化成整数)。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































