
SequoiaDB的查询执行过程
SequoiaDB的查询执行过程
继续读了SDB的代码,重点还是内核的代码。从客户端–查询优化—查询执行的过程来描述一下查询的过程。希望可以搞清楚2个问题:
SDB能做什么查询?
搞清楚SDB是怎么做查询的?
第一个问题的答案是:
理论上,SDB能做mongoDB能做的所有查询,SDB还支持SQL(我指的是SDB内建的支持,不是通过PG支持的查询)
实际上,我没有一个一个去测,SDB看起来mongoDB类的查询基本上完成了;SQL的支持还更像一个玩具。至于说我怎么得到这个结论的,请看下面的分析吧。
至于第二个问题的答案请看下文:
第1部分是技术感言&&吐槽
第2部分是客户端接口。
第3部分是Json查询分析。
第4部分是SQL查询分析。
最后闲扯一下SDB和mongoDB的对比。
注意:
本文涉及到查询解析/优化/执行都是指的是单机版本或者分布式条件下数据节点。基本不涉及CoodNode上的解析部分。
内容以我感兴趣&&能看懂为主,受限于我的水平/工作经历/对某数据库的怨念,不保证内容的正确性,也不保证是系统的精华部分,更不代表SDB官方(他们一毛钱都没给我)。
文中提到的mongoDB是2.6.1版本。
虽然SDB支持事务,但是本文不涉及事务相关的内容。
1. 技术感言
就我看来:SDB就是一个json模型的关系数据库。具体说就是分布式关系数据库(DB2)和以mongoDB为代表的key-document数据库的杂交产物。(DB2出身的人受了mongoDB的启发搞出来的东西?)
目前看来,SDB只搞定了mongoDB相关的东西,SQL那面还没完全搞定(当然搞定SQL很难了)。鉴于SDB已经有一个简单的SQL框架,我猜SDB可能打算同时支持mongoDB的接口和一个SQL子集,以弥补mongoDB接口的不足(比如mongoDB不支持join,而join在OLAP的场景下还是很有用的)。
数据库,尤其是没明显bug的的数据库,是很难搞的;加上事务就更难搞;加上分布式愈加难搞;加上周边支持,几乎就搞不定了;最后把它卖出,几乎是不可能的,历史上成功的公司不多,比如Oracle。SDB想json/SQL通吃,只能说前途是光明的,道路是XXX的。
问题和可能的改进
BSON的限制是16MB,问题是如果用户的数据超过了16MB怎么办?(我指的是单个json文件超过16MB)。当然mongoDB也解决不了这个问题,目前只能在应用层去解决,应用层解决就需要N个json做join的高效方式。
BSON这种自解释的结构好处就不多吹了。但Bson存在着数据量偏大的问题。比如:{‘name‘:‘zhangsan‘, ‘age‘:16}。这个包在网络上传输和解析都没有什么问题。问题在于它存储在collection里的时候,相同的key会重复n多次。当然可以把’name‘简化成’n’:问题是英文字母只有26个,而且过短的名字基本表达不了什么含义。我方案是bson保存在数据库里的时候可以考虑把key转换成id,在返回给用户之前在把它还原成key。这样做可以减少io(当然同时增加了cpu和系统复杂性)。
底层的内存分配基本上都是直接使用的malloc/free, 在代码中也大量的使用了stl,比如vector之类的。而没有使用memoryContext。好处是简化了开发,坏处是glic的ptmalloc有的时候不靠谱的,比如这个坑。理论上讲,这么做一方面存在内存泄漏的危险,另一方面故障率可能会提升。这种内存管理方式和mmap结合起来早晚是个坑,坑到啥程度不好说,但终归是个隐患。老一代的数据库系统,比如pg,mysql等等有自己buffer 管理和memoryContext管理不是没有道理的。(PS. SDB号称核心代码都不用STL,应该是为了避免我说的问题吧)
吐槽
ms 开源代码里doc文件夹被删掉了,删除时间在14年12月31日,这个新年礼物可不怎么好。作为一个开源项目,有doc是应该的。国内的做数据库人才不多,做出一个完整产品的更少。说老实话大牛们不会抄,不牛的想抄的其实也抄不明白。
再次吐槽简写,代码里的简写实在看不懂。作为这个世界上最不会起名字的码农,我实在猜不出来很多缩写是啥,虽然我能猜出它是干嘛的。
除了对外接口,在内部的很多函数中也使用了BsonObj,个人认为这是个双刃剑了:一方面在写代码的时候确实方便;另外一方面时间长了,这个参数就变成一个大箩筐,里面什么都有。设想一个场景:如果一个函数里面10几20几个参数的话,会引发无数吐槽;但是如果用一个BsonObj当参数,可
缩写列表
泪流满面的是,我找到了部分缩写的对应关系:
auth : Authentication
bps : BufferPool Services
cat : Catalog Services
cls : Cluster Services
dps : Data Protection Services
mig : Migration Services
msg : Messaging Services
net : Network Services
oss : Operating System Services
pd : Problem Determination
rtn : RunTime
sql : SQL Parser
tools : Tools
bar : Backup And Recovery
client : Client
coord : Coord Services
dms : Data Management Services
ixm : Index Management Services
mon : Monitoring Services
mth : Methods Services
opt : Optimizer
pmd : Process Model
rest : RESTful Services
spt : Scripting
util : Utilities
作为一个不会起名字的人,我表示很欣慰。
2. 客户端
网络传输
第三方库
使用的是boost的库,在boost的基础上实现了同步/异步的传输。
协议
网络传输协议的头是MsgHeader。
struct _MsgHeader
{
SINT32 messageLength ; // total message size, including this SINT32 opCode ; // operation code UINT32 TID ; // client thead id MsgRouteID routeID ; // route id 8 bytes UINT64 requestID ; // identifier for this message } ; typedef struct _MsgHeader MsgHeader ;
在这个头的基础上,会有更多的结构出来,比如MsgOpQuery,MsgOpGetMore,MsgOpDelete等等。
这个header其余部分都好理解,主要说明两个东西
opCode 在msg.h里的enum MSG_TYPE中有详细定义,这里不拷贝了,有意思的是request和reply的id是基本上对应的: #define MAKE_REPLY_TYPE(type) ((UINT32)type | 0x80000000), 比如 MSG_BS_INSERT_REQ = 2002, MSG_BS_INSERT_RES = MAKE_REPLY_TYPE(MSG_BS_INSERT_REQ),.
routeID 路由的id
union _MsgRouteID
{ struct {
UINT32 groupID ;
UINT16 nodeID ;
UINT16 serviceID ;
} columns;
UINT64 value ;
} ;
其中,servieId是:
typedef enum _MSG_ROUTE_SERVICE_TYPE { MSG_ROUTE_LOCAL_SERVICE = 0, MSG_ROUTE_REPL_SERVICE,
MSG_ROUTE_SHARD_SERVCIE,
MSG_ROUTE_CAT_SERVICE,
MSG_ROUTE_REST_SERVICE,
MSG_ROUTE_OM_SERVICE,
MSG_ROUTE_SERVICE_TYPE_MAX
}MSG_ROUTE_SERVICE_TYPE;
至于说_MsgRoutId之所以是一个union,原因在于MsgRouteID毕竟是一个id,把他当作id来用的时候,不免要涉及到compare,使用value就比较方便了,并且性能也更好。
Json API
json api其实没有多少好说的,托js的福,实际上在客户端就已经完成了传统数据库parse的过程,不用yacc/lex一番,也不用定义一堆类似于xxxValue,xxxTable,xxxRef,xxxFun,xxxItem之类的东西,统统都是BsonObj就可以。让我们看一下query的接口
virtual INT32 query ( sdbCursor &cursor, const bson::BSONObj &condition = _sdbStaticObject, const bson::BSONObj &selected = _sdbStaticObject, const bson::BSONObj &orderBy = _sdbStaticObject, const bson::BSONObj &hint = _sdbStaticObject, INT64 numToSkip = 0, INT64 numToReturn = -1, INT32 flag = 0 ) = 0 ;
SQL API
sql的接口和关系数据库差不多。
virtual INT32 exec( const CHAR *sql, sdbCursor &result ) = 0 ;
postgresql API
安装文档。
本质上,postgresql的插件就是一个client程序,有点类似于mysql Federated引擎,就是一个代理。
至于性能能达到什么程度不好说。但是作为一个噱头或者说添头足够了。
用一个很低的成本完成了对SQL的支持。SDB自身也是支持SQL,虽然还不成熟
没有去细看storm/hive/hadoop什么的,猜测实现方式类似。
3. Json接口查询过程
json接口这个称呼可能不够准确,就是mongoDB那样的接口。
整体流程
下图是我自己画的, 中间过程名字是我自己起的,不大严谨。

解析
json没有什么好解析的,语法树已经传过来了。
对于json接口来说入口在rtnQuery,最终会得到一个物理查询计划。(这个说法其实不够严谨,类似group by的操作是在rtnAggregate里面完成的,这里忽略吧)
生成查询计划
其输出 optAccessPlan是比较复杂的class,对应着具体的查询计划。
INT32 _rtnAccessPlanManager::getPlan ( const BSONObj &query,
const BSONObj &orderBy,
const BSONObj &hint,
const CHAR *collectionName,
optAccessPlan **out ) class _optAccessPlan : public SDBObject
{ private:
dmsExtentID _indexCBExtent ;
dmsExtentID _indexLID ;
OID _indexOID ; // the oid for the index, for validation mthMatcher _matcher ; // matcher that should be used by the plan rtnPredicateList *_predList ; // predicate list that generated from _dmsStorageUnit *_su ; // pointer for the storage unit _rtnAccessPlanManager *_apm ; // parent access plan manager CHAR _collectionName[ DMS_COLLECTION_NAME_SZ+1 ] ; CHAR _idxName[IXM_KEY_MAX_SIZE + 1] ;
BSONObj _orderBy ; // order by called by the user BSONObj _query ; // query condition called by the user BSONObj _hint ; // hint called by the user BOOLEAN _hintFailed ;
INT32 _direction ; // direction called by the user optScanType _scanType ; BOOLEAN _isInitialized ; BOOLEAN _isValid ; BOOLEAN _isAutoPlan ; // auto plan, TRUE when the plan is not UINT32 _hashValue ;
ossAtomicSigned32 _useCount ; BOOLEAN _sortRequired ; // whether we need to explicit sort the resultset ....
_rtnAccessPlanManager::getPlan 的逻辑很简单:
planCache里有对应build参数的计划,如果有则返回;
否则build一个新的计划。
在build的过程中夹杂了一个非常重要的函数:

其中cost的估算方法在
INT32 _optAccessPlan::_estimateIndex ( dmsExtentID indexCBExtent, INT64 &costEstimation, INT32 &dir, _estimateDetail &detail ) .... orderFactor = 1.0f - ((nFields == 0) ? (0) : (((FLOAT32)matchedFields)/((FLOAT32)nFields))); orderFactor = OSS_MIN(1.0f, orderFactor) ; orderFactor = OSS_MAX(0.0f, orderFactor) ; ..... if ( nFields == 0 || nQueryFields == 0 ) queryFactor = 1.0f ; else queryFactor = 1.0f - ((FLOAT32)matchedFields)/ (OSS_MIN(((FLOAT32)nFields),((FLOAT32)nQueryFields))) ; queryFactor = OSS_MIN(1.0f, queryFactor) ; queryFactor = OSS_MAX(0.0f, queryFactor) ;
个人理解就是index的选择尽量和条件/order保持一致。
openCursorBaseOnPlan
实际上调用的是下面的函数,基本根据scan的类型,打开响应的table/index。注意scan过程根本没有真正获取任何数据,只是拉开架势准备scan而已。
INT32 _rtnContextData::open( dmsStorageUnit *su, dmsMBContext *mbContext,
optAccessPlan *plan, pmdEDUCB *cb, const BSONObj &selector, INT64 numToReturn,
INT64 numToSkip, const BSONObj *blockObj,
INT32 direction )
.... if ( TBSCAN == plan->getScanType() )
{
rc = _openTBScan( su, mbContext, plan, cb, blockObj ) ;
PD_RC_CHECK( rc, PDERROR, "Failed to open tbscan, rc: %d", rc ) ;
} else if ( IXSCAN == plan->getScanType() ) {
rc = _openIXScan( su, mbContext, plan, cb, blockObj, direction ) ;
PD_RC_CHECK( rc, PDERROR, "Failed to open ixscan, rc: %d", rc ) ;
}
...
查询执行
对于Json接口而言,在rtnQuery的时候,除了build好了plan其实什么都没有做。真正开始执行的时候:会辗转调用到下面的函数,基本上这个函数的主要用途就是,基本上就是调整游标到指定的位置,然后把结果放到bufferObj里面去。
INT32 _rtnContextBase::getMore( INT32 maxNumToReturn, rtnContextBuf &buffObj, pmdEDUCB *cb )
具体的工作实际上是由
class _dmsScanner : public SDBObject
{ public:
_dmsScanner ( _dmsStorageData *su, _dmsMBContext *context,
_mthMatcher *match,
DMS_ACCESS_TYPE accessType = DMS_ACCESS_TYPE_FETCH ) ; virtual ~_dmsScanner () ; public: virtual INT32 advance ( dmsRecordID &recordID,
ossValuePtr &recordDataPtr,
_pmdEDUCB *cb, vector<INT64> *dollarList = NULL ) = 0 ;
}
完成的,对于table,index都有自己的实现。注意还同时处理了事务,skip,match之类的,所以代码看起来有点混乱。由于SDB底层实际上是由mmap实现的,内存结构和存储结构是一致的。
4. SQL接口的查询过程
SQL解析
详细的语法定义请见:engine/include/SQlgrammer.hpp, 具体支持的方式不是传统的yacc而是boost的spirit库。这里有一篇中文的简介。解析器生成程序遵循 Extended Backus Naur Form (EBNF) 规范并使用 C++ 编写。简单说这是一个简化版的yacc。
我猜测SDB应该不会花大力气去支持什么SQL 2008之类的标准,应该只是支持简单的SQL语法,最终完成SQL和Json的某种和解。最大可能是像hive一样,搞自己的SQL玩儿:叫SSQL?
查询优化
下面的文字来源于我自身感悟,和SDB完全无关,和这篇文章关系都不大,也不保证正确性。
所谓查询优化,既可以理解成一般意义上优化,也可以狭义理解成针对查询计划生成的优化。比如采用group commit可以有效减少io,让查询变得更快,这属于前者;在一堆index中选择一个selectivity最小的索引生成相应的查询计划,则属于后者。本文所指的查询优化是后者。
查询优化有基于规则的方法,有基于代价的优化方法,或者两者的结合。真正做的极致的系统其实很少很少。感兴趣的同学请参考 http://blog.163.com/li_hx/。基本上PG和Mysql有些事情做的也很土。
一个好的优化器,不仅仅应该完成优化任务,更重要的是要清晰,正交,可维护,可配置,易调试。
突然想起见过的一个的MPP SQL优化器,输入是一个SQL语句,输出是一系列的SQL语句,可以直接拿到目标数据节点上执行。完全就是用一个又一个的规则的结合,在Mysql那一团麻的优化比起来,嗯,可以说是汇编语言和Java的区别。印象中也是DB2的人写的。
闲扯一句,对于查询优化这种事儿来说,用C++开发似乎不是什么好的主意。虽然主流数据库都是这么做的,但是现在的编程语言选择比Oracle,DB2出道的那个时代丰富多了。更重要的是查询优化也不怎么涉及底层操作,c/c++剩下的唯一好处也许就是和其它的代码可以共用一套数据结构这个优势了;不过坏处却很明显:容易core,编程复杂,很多东东没有内建的语言支持等等。嗯,找不到一个会其它语言的程序员,拜托,能搞定查询优化的程序员会care学习新的语言?
扯远了,书归正传。下面的内容包括:
根据语法树构造逻辑执行计划。(相对容易)
世面上的SQL数据库应该有个过程是把逻辑执行计划变成等价的逻辑查询计划(比如out join to inner join之类的,根本目的是把查询变简单)。似乎SDB没有这个过程(也许有,我没注意)
构造物理查询计划(容易)如果有若干个可行的查询计划,选出其中最好的一个。(很难的问题)
不包括查询执行(真正从磁盘上获取数据),相关内容会在查询执行章节介绍。
查询优化的流程
入口在_pmdDataProcessor::_onSQLMsg–> _sqlCB::exec
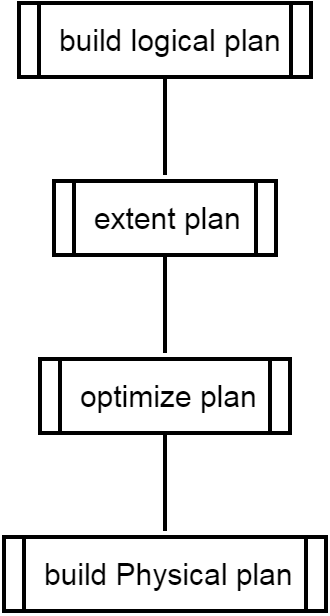
步骤1 逻辑查询计划的生成(buildLogicPlan)
qgmBuilder builder( container->ptrTable(), container->paramTable()) ; rc = builder.build( container->ast().trees, opti ) ;
具体可以看_qgmbuilder的build函数
public: // INT32 build( const SQL_CONTAINER &tree, _qgmOptiTreeNode *&node ) ;
最终的结果会得到一个逻辑语法树,实现的很经典。关于语法树的定义如下:
class _qgmOptTree : public SDBObject
{ private:
qgmOptiTreeNode *_pRoot ;
qgmPtrTable *_prtTable ;
qgmParamTable *_paramTable ;
...
} class _qgmOptiTreeNode : public SDBObject
{ friend class _qgmOptTree ; public:
.... public:
qgmOptiTreeNodePtrVec _children ;
qgmField _alias ;
_qgmOptiTreeNode *_father ;
QGM_OPTI_TYPE _type ;
BOOLEAN _releaseChildren ;
_qgmPtrTable *_table ;
_qgmParamTable *_param ;
QGM_HINS _hints ; protected:
qgmOprUnitPtrVec _oprUnits ; private:
UINT32 _nodeID ;
} ;
其中几个基础元素是:
class _qgmField : public SDBObject
{ private: const CHAR *_begin ;
UINT32 _size ;
...
class _qgmDbAttr : public SDBObject
{ public:
_qgmDbAttr( const qgmField &relegation, const qgmField &attr )
:_relegation(relegation),
_attr(attr)
{
}
... typedef vector< qgmDbAttr* > qgmDbAttrPtrVec ; typedef vector< qgmDbAttr > qgmDbAttrVec ; struct _qgmOpField : public SDBObject
{
qgmDbAttr value ;
qgmField alias ;
INT32 type ;
... typedef std::vector< qgmOpField > qgmOPFieldVec ; typedef std::vector< qgmOpField* > qgmOPFieldPtrVec ;
至于说怎么把一个ast结构变成一个_qgmTreeNode的过程,具体过程参考class _qgmBuilder::build。是一个比较复杂&&机械的过程,这里就不赘述了。
步骤2 extend
rc = opti->extend( extend ) ;
extend是干什么的呢?
opti的类型是_qgmOptiTreeNode,实际上是上一步得到的逻辑语法树根节点,extend实际上就是依次调用children nodes的extend函数,和自己的_extend函数。实际上extend完成了语法树的后根遍历过程。
_extend是个虚函数,所有opiTreeNode都有自己的实现,但是实际的逻辑其实是在各种各样的qgmExtendPlan里面实现的。
class _qgmExtendPlan : public SDBObject
{ public:
_qgmExtendPlan() ; virtual ~_qgmExtendPlan() ; public: INT32 extend( qgmOptiTreeNode *&extended ) ; INT32 insertPlan( UINT32 id, qgmOptiTreeNode *ex = NULL ) ; protected:
QGM_EXTEND_TABLE _table ;
qgmOptiTreeNode *_local ;
UINT32 _localID ;
std::queue<qgmField> _aliases ;
} ; typedef class _qgmExtendPlan qgmExtendPlan ;
那么说了这么多废话,extend究竟是干嘛的?我理解:extend就是把简单的逻辑概念变得具体一点。比如(这个例子不大严谨)qgmExtendSelectPlan就会把select a from t group by a;扩展成:

吐槽一句,难道这个extend不应该塞到build里吗?我以为这个是啥高级方法来着。
步骤3 optimize
_optQgmOptimizer optimizer ; rc = optimizer.adjust( tree ) ;
注意一点这个函数称之为adjust而不是optimize,实际上adjust真的是adjust。基本上adjust干的事情就是把field和condition adjust到它们应该在的位置上面去。举例来说select t1.a,t2.a from t1 join t2 on t1.b=t2.b where t1.c > 10; ,adjust的目的就是t1.a 和 t1.c下推成select t1.a, t1.b from t1 where t1.c > 10。 当然事实比这个例子复杂的多。
ajust之后的类型包括:
enum QGM_OPTI_TYPE {
QGM_OPTI_TYPE_SELECT = 0 ,
QGM_OPTI_TYPE_SORT,
QGM_OPTI_TYPE_FILTER,
QGM_OPTI_TYPE_AGGR,
QGM_OPTI_TYPE_SCAN,
QGM_OPTI_TYPE_JOIN,
QGM_OPTI_TYPE_JOIN_CONDITION,
QGM_OPTI_TYPE_INSERT,
QGM_OPTI_TYPE_DELETE,
QGM_OPTI_TYPE_UPDATE,
QGM_OPTI_TYPE_COMMAND,
QGM_OPTI_TYPE_MTHMCHSEL, // with matcher的select
QGM_OPTI_TYPE_MTHMCHSCAN,
QGM_OPTI_TYPE_MTHMCHFILTER,
QGM_OPTI_TYPE_SPLIT,
QGM_OPTI_NODE_MAX
} ;
adjust逻辑分散在各个optQgmStrategyBase和各个_qgmOptiTreeNode中。在_optQgmStrategyTable::init中描述了当前的所有optQgmStrategyBase。
class _optQgmStrategyBase : public SDBObject
{ public:
_optQgmStrategyBase () {} virtual ~_optQgmStrategyBase () {} public: virtual INT32 calcResult( qgmOprUnit *oprUnit,
qgmOptiTreeNode *curNode,
qgmOptiTreeNode *subNode,
OPT_QGM_SS_RESULT &result ) = 0 ; virtual const CHAR* strategyName() const = 0 ;
}; typedef _optQgmStrategyBase optQgmStrategyBase ;
实际上,这里没有optimize只有ajust。还没有函数好意思叫自己optimize?ajust只完成了最基本的SQL功能,真正的优化还没有开始。
步骤4 生成物理查询计划
INT32 build( _qgmOptiTreeNode *logicalTree, _qgmPlan *&physicalTree) ;
具体的build过程就是遍历上一步得到的logicalTree,得到physicalTree的过程。
最终的到的_qpmPlan
class _qgmPlan : public SDBObject
{ public:
_qgmPlan( QGM_PLAN_TYPE type, const qgmField &alias ) ; virtual ~_qgmPlan() ; private: virtual INT32 _execute( _pmdEDUCB *eduCB ) = 0 ; virtual INT32 _fetchNext( qgmFetchOut &next ) = 0 ;
物理计划的类型包括
enum QGM_PLAN_TYPE { QGM_PLAN_TYPE_RETURN = 0, QGM_PLAN_TYPE_FILTER,
QGM_PLAN_TYPE_SCAN,
QGM_PLAN_TYPE_NLJOIN,
QGM_PLAN_TYPE_INSERT,
QGM_PLAN_TYPE_UPDATE,
QGM_PLAN_TYPE_AGGR,
QGM_PLAN_TYPE_SORT,
QGM_PLAN_TYPE_DELETE,
QGM_PLAN_TYPE_COMMAND,
QGM_PLAN_TYPE_SPLIT,
QGM_PLAN_TYPE_HASHJOIN,
QGM_PLAN_TYPE_MAX,
} ;
基本上和上面的逻辑查询计划一一对应的mapping就行。顺便说一句,join的物理查询计划有两种方法,nest loop和hash join(终于不纠结缩写了),build哪一个呢?答案居然是这样的:
if ( join->_hints.empty() )
{
phy = SDB_OSS_NEW _qgmPlNLJoin( join->joinType() ) ; if ( NULL == phy )
{
PD_LOG( PDERROR, "failed to allocate mem." ) ;
rc = SDB_OOM ; goto error ;
}
} else {
phy = SDB_OSS_NEW _qgmPlHashJoin( join->joinType() ) ; if ( NULL == phy )
{
PD_LOG( PDERROR, "failed to allocate mem." ) ;
rc = SDB_OOM ; goto error ;
}
}
虽然有效,但是有点低级的说。
查询执行
同json接口一样,query只是build好了逻辑执行树,getMore才触发每个物理操作的_fetchNext操作获取。
以qgmPlScan(scan操作)来说:
在data node上就是一个scan操作了,基本上执行select xxx from xxx where xxx order by xxx的工作,其实它干的活都是_dmsScanner干的(参考上面的json接口)。它只是一个wrap而已。
在cood node上,它干的事儿其实是拼一个请求,发送到具体的data node上。
rc = msgBuildQueryMsg ( &qMsg, &bufSize, _collection.toString().c_str(),0, 0, _skip, _return, &_condition, &selector, &_orderby, &_hint ) ;
小结
整体来说,这个SQL框架还是很不错的,虽然现在还很简单,但是还是有很大发展空间的。至于最终这玩意儿是个玩具还是个利器就要看SDB的开发者的水平&&市场需求了。
多扯一句,分布式SQL解析优化这条路不好走,很难很难啊。在hint的道路上大步前进也不错。
回到本文开头的两个问题上来,从理论上SDB是具备把Json和SQL有效结合起来的可能性的。最终可能出现这样一个数据库:
它支持SQL:你可以用SQL语句直接CRUD。
它支持分布式,支持HA等时髦概念。
它多少支持那么一点事务。虽然不如传统关系数据库,甚至在极端情况下会出错,不过总比一点事务没有强。
一家之言,随便说说
VS mongoDB
网上有一篇访谈,【先锋】SequoiaDB CTO王涛谈打造超越MongoDB的事务、高性能NoSQL。这是SDB自己的说法。
我个人的理解如下:
代码层面
| Item | SDB | MongoDB |
|---|---|---|
| 代码规模 | 太多了,不知道里面放了些什么,核心的source其实没那么多,至少不应该上百兆,我试着在我的VPS上git clone,build,然后我可怜的VPS就满了。 | mongoDB的代码显得更加简洁一些,至少源码包小得多。 |
| 代码注释 | 我能说看代码基本靠猜嘛? | 相对来说mongoDB的代码注释就大方多了。当然也有一些很奇怪的地方,比如所有的error code都是直接写的数字,不过瑕不掩瑜。 |
| 代码的个人观感 | 窃以为mongoDB代码的目的性很强,需要干嘛就干嘛。实用性气息重些,不大像传统数据库的写法。好处就是好读一些。 | 相对来说SDB学院气就重了点,代码显得也高大上一点,有传统数据库的影子在;副作用就是没背景&文档的话,难读一点。 |
如果只是想看看key-document数据库怎么写,建议读mongoDB
设计
| Item | SDB | MongoDB | 点评 |
|---|---|---|---|
| Json接口 | 应该是山寨的mongoDB | 基本上实现了select/order/groupby | 一样一样的啊 |
| SQL接口 | 算是支持吧 | 不支持,基本上没有支持的可能了 | 能支持SQL当然好,问题是很难啊 |
| 文件系统 | mmap | mmap | 不是说mmap不好,至少不那么可控,两家都用的原因是比较简单? |
| 事务 | 支持,虽然隔离级别为 UR | 不支持 | 传统企业没有事务会死人的 |
| 锁 | 应该在document上吧 | 数据库级,至少2.6依然如此,无数的人吐槽,2.6里的代码里面, Lock::DBWrite lk(ns.ns());出现在了很多不应该它出现的地方 | 著名的mongoDB坑,不知道为啥这么久还没解决 |
| 数据分片方式 | 一致性hash | Mongodb数据分片方式有hash和range两种方式,当一个chunk的大小超过配置时,Mongodb会将过大的chunk一分为二,然后将chunk在负载差别过大的分片群组(Shard)之间进行自动的迁移。据说数据多了,mongo hash的并不好 | 一致性hash显然是更好的方案 |
性能
作为一个懒人&&穷人。我承认我没测,csdn上有这样一份数据。简单总结下,结论就是SDB写比MongoDB快;mongoDB读快,不过SDB也差不太远;读写混合情况下,SDB好一点;hbase读写都不怎么样。
这种稿子都是有PR嫌疑的,具体数字当不得真,但是几个定性的结论还是可以说一下的:
受mongo那个伟大的锁的影响,凡是涉及到并发写mongoDB都不怎么样。
Hbase的下层是hdfs,怎么折腾也搞不过mongoDB和SDB的mmap。
小结
不得不承认,SDB站在了mongoDB的肩膀上。
mongoDB虽然有坑,但是这么多年来,无数人已经踩过了,大不了有坑绕着走;SDB则存在着未知的,还没有被大家踩过的坑。
从设计上看,SDB比mongoDB更优;从实现上看SDB至少不比mongoDB。
从成熟度上,大家都不怎么样;窃以为大家的版本号上都应该加个0.。
一句话总结
SDB就是一个json模型的关系数据库。
不会这个就是他们创业的idea吧?
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































