
使用 HAProxy, PHP, Redis 和 MySQL 轻松构建每周上亿请求Web站点
英文原文:The Easy Way Of Building A Growing Startup Architecture Using HAProxy, PHP, Redis And MySQL To Ha...
本案例是由Antoni Orfin写的客座文章,他是Octivi的联合创始人和软件架构师。
在文章中,我将向您展示我们开发的基于HAProxy,PHP,Redis和MySQL的非常简单的架构的方法,它可以无缝地处理约每周十亿次的请求。文章中还列举了进一步扩展它的可能途径,并指出了针对于该项目的不常见的模式。
数据:
-
服务器:
-
3x 应用节点
-
2x MySQL + 1x 用于备份
-
2x Redis
-
应用程序:
-
应用程序每周处理1,000,000,000请求
-
单一Symfony2实例达到700req/s(工作日平均550req/s)
-
平均响应时间 - 30 毫秒
-
Varnish - 高于12,000 req/s (在压力测试中达到)
-
数据存储:
-
Redis - 160,000,000记录, 100 GB 的数据 (我们主要的数据存储库!),
-
MySQL - 300,000,000记录 - 300 GB (第三层缓存)
平台:

-
监控:
-
Icinga
-
Collectd
-
应用程序:
-
HAProxy with Keepalived
-
Varnish
-
PHP (PHP-FPM) with Symfony2 Framework
-
数据存储:
-
MySQL (master-master) with HAProxy load balancing
-
Redis (master-slave)
-
背景
差不多一年前,我们的朋友带着一个难以解决的问题来到我们的办公室。他们正在运行一个快速增长的电子商务新兴公司,当时他们希望将其扩展到国际水平。
因为他们仍然是一个新兴的公司,提出的解决方案必须是高性价比的,而不是在下一个服务器上将钱用完。遗留系统一直采用标准的LAMP架构搭建,他们已经有一个强大的PHP开发团队。新技术的引进必须要精巧,不能是过于复杂的架构,并且能让他们现有工作人员进一步维护此平台。
系统体系结构必须被设计为可扩展的方式,来实现扩展到下一个市场的计划。所以我们只好来了,检查他们的基础设施...
-
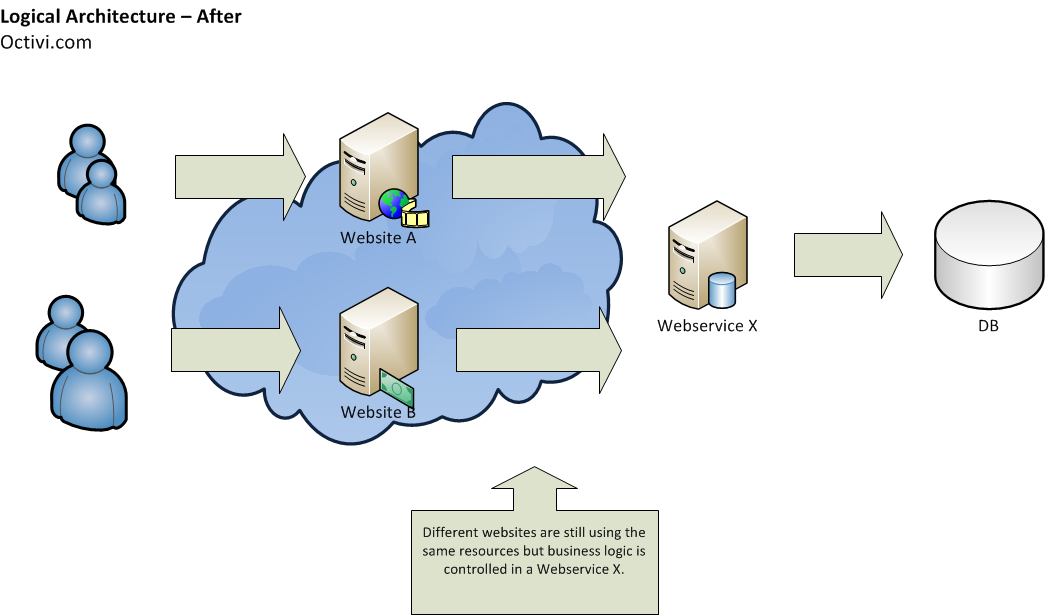
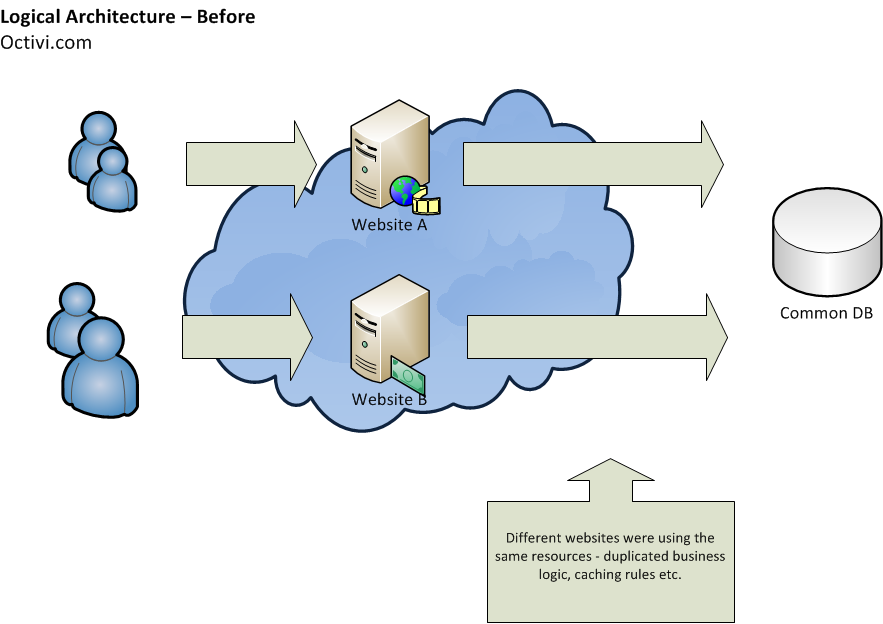
以前的系统是以整体方式设计的。具体来说是一些独立的基于PHP的Web应用程序(在新兴公司有很多所谓的前端网站)。他们中的大多数都使用单一的数据库,他们共享一些常见的代码来处理业务逻辑。
进一步维护这样的应用可能是一个噩梦。由于部分代码已经被复制,更改一个网站,可能会导致业务逻辑的不一致 - 他们总是需要在所有的web应用程序中进行相同的更改。
此外,从项目管理的观点来看这也是一个问题 - 谁应该负责被分散在多个代码库的“那一部分”代码呢?
-
根据这一观察,我们的第一步是提取核心的关键业务功能到一个单独的服务中(这是本文的范围)。它是面向服务的架构模式。在整个系统范围内考虑“关注点分离”的原则。该服务是保持一种逻辑的,具体的更高级别的业务功能。给你一个真实的例子 - 服务可以是一个搜索引擎,销售系统等。
前端网站通过一个REST API来和服务进行通信。响应是基于JSON格式的。我们选择它的原因是简单性,相反SOAP始终对开发者来说比较困难(没有人喜欢分析XMLS...;-))
提取的服务并不处理如身份验证和会话管理之类的东西。这是必须的,这些事情是在一个更高的层次来处理的。前端网站负责这一点,因为只有他们才能确定他们的用户。这样,我们将服务更简化 - 在进一步扩展的问题和代码的东西上。没有什么不好的,因为它有不同的任务来处理。
-
优点:
- 不同的子系统(服务)可以很容易被完全不同的开发团队开发。开发者之间可以互不干涉。
- 不用处理用户授权和访问问题,因此就不存在常见的等级问题了。
- 在一个地方维护业务逻辑-不同的前端网站之间不存在冗余的功能。
- 易于该服务被大众所接受。
缺点:
- 系统管理者的工作量更大- 因为服务是基于其自身的架构体系,所以系统管理员就需要对该架构增加关注。
- 保持向后兼容性-在一年的维护中,API 方法的改变多的会不计其数。 问题是这些改变千万不能破坏向后兼容性,不然每个前端网站的代码都需要修改,而且同时部署所有网站时会增加程序员工作...一年之后,所有的方法仍然能够与第一版的文档兼容。
-
应用层

根据请求流,第一层是应用层,应用层里面包括HAProxy负载均衡器,Varnish和Symfony2 网络应用。来自前端网站的请求首先到达HAProxy,然后通过HAProxy分发到应用节点中。
应用节点配置
-
Xeon [email protected], 64GB RAM, SATA
-
Varnish
-
Apache2
-
PHP 5.4.X running as PHP-FPM, with APC bytecode cache
我们已经拥有三个这样的应用服务器。它是双活模式下的N+1模式 - ”备份“服务器主动处理请求。
保持Varnish在每个节点中的独立性使得快取命中率更低,但是这种方式下我们就不存在SPOF问题(一个节点失效,全部系统停止运转)。我们这样做的目的是考虑可用性高于性能(在我们的案例中性能不是问题)。
我们选择Apache2,它也被用在前端网站服务器中。避免混合进许多技术使得系统管理员的维护更加容易。
-
-
Symfony2 应用
应用本身是建立在Symfony2的顶层之上。它是一个完全PHP的栈框架,提供丰富的有用组件,这些组件能够加速开发的进程。将典型的REST服务建立在一个复杂的框架之上可能对某些人来说不可思议,让我对其中的原因进行说明:
-
易于PHP/Symfony开发者接受 - 客户的IT团队包括PHP开发者。引入新技术(比如Node.js)就意味着需要雇佣新的能够更好的维护系统的开发者。
-
清晰的项目结构 - Symfony2并没有利用非常复杂的项目结构,但它缺省的项目结构非常清晰。招聘新的开发者进入工程是非常简单的,因为Symfony2的代码对他们来讲非常熟悉。
-
现成的组件 - 遵循DRY理念... 没有人想去重新构造,所以我们也不想。我们广泛使用Symfony2的控制组件,该组件对于生成CLI命令、制作应用(调试工具栏)性能分析工具以及记录器等是一个非常棒的框架。
在使用之前,我们做了性能测试以确保其能够处理设定好的任务量。我们开发了概念验证模型并使用它运行JMeter。结果令人印象深刻-700req/s的响应时间最高50ms。这是我们确信,在我们的这个项目中可以使用这一复杂结构。
-
-
应用分析与监控
我们使用了Symfony2的工具来监控我们的应用。Symfony2有一个非常棒的性能分析组件,可以用来收集特定方法的执行时间,尤其是那些与第三方服务有关的方法。这样我们就可以找出潜在的弱点以及应用中最耗时的部分。
详细的日志是必须的。为此,我们使用PHP的Monolog库,它允许我们生成友好的、完全能够被开发者和系统管理者理解的格式化日志记录。必须时常谨记的是日志中要尽可能的增加细节,我们发现日志越详细越好。我们使用了不同的日志级别:
-
调试 - 一些将要产生的信息 - 比如在调用外部网络服务之前的请求信息;一些已经发生的信息-从API请求返回的响应;
-
错误 - 出现了错误但是请求流还没有停止(比如从第三方API返回的错误响应);
-
危险 - 哎呦… 应用崩溃了。
在产品环境下,你能够看到Error级别日志,以及它下面的Critical级别日志。在开发/测试环境中,还有Debug日志可以看到。
我们将日志分成不同的文档(在Monolog库中他们被称为“通道”)。主日志文件用于存储所有应用范围的错误信息以及特定通道中的短日志信息。我们将来自不同通道中的详细日志信息保存在不同的文件中。
-
-
可扩展性
扩展平台上的应用层级并不是件难事。 HAProxy的性能并不会被常时间的消耗,我们只需要考虑避免单点故障(SPoF) 所需的冗余。
在此模式下只需要增加其他应用节点即可。
数据层
我们使用Redis和MySQL存储所有的数据。当Redis做为主数据存储时,MySQL则用于第三层的缓存存储。
-
Redis
当设计我们的系统时,我们需要考虑选择一个能够满足我们设定要求的数据库:
-
存储大量数据时(约2.5亿记录)不能降低性能
-
主要使用基于特定资源标识符的简单GETs(没有查找或复杂的SELECTs)
-
能够在单个请求中获取大量的资源以最小化延迟
经过一些调查,我们决定使用Redis。
-
我们进行的所有操作的复杂度为 O(1) 或 O(N),N代表我们检索的主键数目。这意味着主键空间的大小不会影响到性能。
-
一次检索的主键数目大于100时我们大多使用MGET命令,与在一次回路中使用多个GETs相比,那样可以忽略网络延迟。
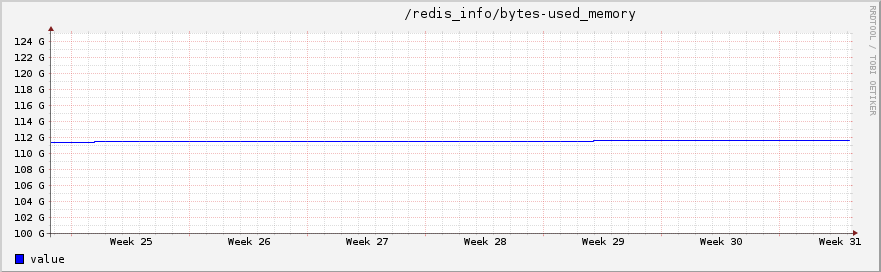
最近我们在主从复制模式下运行了两台Redis服务器。每个的配置为: Xeon [email protected], 128GB, SSD. 内存限制在100GB...内存经常被占满 :-)
-
-
由于应用并没有完全耗尽单一Redis服务器的所有性能,因此从属服务器主要用于备份以及保持(系统)高可用性。一旦主服务器宕机,我们可以轻松地将应用转换到从属服务器上。进行维护工作或者迁移服务器时,复制也是很便利的-服务器的切换非常简单。
你可能疑惑为什么我们的Redis经常处于最大内存状态中。大多数的主键是永久类型的-大约占主键空间的90%。而其余的主键则完全是缓存,我们可以设置他们为TTL(译者注:Time-To-Live)过期。现在,主键空间被分为了两大部分:一部分是拥有TTL设置的(缓存)和另一部分没有TTL设置的(永久数据)。幸亏Redis设置的最大内存策略为“volatile-lru"(译者注:Redis的六种内存策略之一,表示只对设置了过期时间的key进行lru),那些最少使用的缓存主键(也只有这些设置了过期)将被自动删除。(译者注:应该是the least recently used...)
那样的话,我们就可以将单个Redis实例既可以当主要存储使用,也可以当典型缓存使用。
-
使用这一模型时,必须谨记的是要监测“过期”主键的数量。(译者注:以下为命令行查看部分)
db.redis1:6379> info keyspace
# Keyspace
db0:keys=16XXXXXXX,expires=11XXXXXX,avg_ttl=0
当你发现(“过期”主键)数量接近危险值0时,就需要启动切分或者提高内存了;-)
我们如何监视它呢?Icinga检查能够监视”过期“数量是否达到了崩溃点。我们也使用Redis曲线实现”失去主键“比的可视化。
一年之后,我可以说我们已经完全融入了Redis。从这个项目开始,Redis就没有让我们失望过——没有过停机也没有其他事件。
-
MySQL
除了Redis,我们还使用了传统的MySQL数据库。不同的是,我们只用它来做为第三方的缓存层。我们用它来存储哪些会占用Redis太多内存的,在近期不会使用的内容,这样我们就可以把它放在其他的硬盘上。这并不是什么新奇的技术,我们希望能够保持堆栈越简单越好,以便于维护。
我们有两个以上的MySQL服务器,配置为: Xeon [email protected], 64GB RAM, SSD。其中有本机异步主-主复制。以及一台单独的从节点用于备份。
-
MySQL的高可用性
从物理结构图上你可以看出,在每个MySQL框上有HAProxy,并实现了热备。通过HAProxy实现与MySQL的连接。
在每个数据库服务器上安装HAProxy的模式可以确保栈的高可靠性,并且不用为了负载均衡再则更加一台服务器。
HAProxy采用主动-被动模式(同一时间只有一个运行)运行。热备机制可以控制他们的可用性。在热备的控制下有一个浮点IP(VIP),它可以检查主负载均衡节点的可用性。当主节点崩溃时,第二(从属)HAProxy节点就会接管这个IP。
-
可扩展性
数据库通常是一个应用中最大的瓶颈。一般地,没有必要进行向外扩展操作——此次,我们通过增大Redis和MySQL空间来进行纵向扩展。虽然Redis运行在拥有128GB内存的服务器上,还有剩余空间——(但是)将他们迁移到拥有256GB内存的节点上是可行的。当然大容量也会给一些操作带来不便,比如快照或者运行服务器——启动Redis服务器将花费更长的时间。
纵向扩展之后,我们进行(横向)外部扩展。可喜的是,我们已经为我们的数据准备好了简单的分割结构。
Redis中我们有4”重“记录类型。记录可以根据数据类型被分到四个服务器中。我们不想根据哈希进行分割,而更乐于根据记录的类型进行分割。这种方式使得我们仍然可以使用通常对一类主键表现良好的MGET。
在MySQL中,数据表采用便于向不同服务器迁移的结构进行存储——这些数据表也是基于记录类型(存储的)。
在分析完根据数据类型分割数据的优势后, 我们来看看哈希。
-
经验教训
-
不要共享你的数据库 - 曾经,有一个前端网站想要将其会话处理转换到Redis。他们就连接到了我们的数据库上。这使得我们的Redis缓存空间被用尽,我们的应用也被拒绝存储缓存主键。所有的缓存开始只存储到MySQL服务器上,这导致MySQL服务器的系统开销过大。
-
要有详细的日志 - 当没有足够的日志信息时,你就不能很快的调试出哪里出了问题。有一次,由于缺少某个信息,我们找不到产生这个问题的原因,不得不等该问题再一次出现(在增加了需要的日志信息后)。
-
使用复杂架构并不意味着会“降低网站(速度)” - 有些人可能会对使用全栈架构来处理每秒如此数量的请求感到惊讶。这全在于你(如何)巧妙地使用你拥有的那些工具——即使在Node.js上你也能运行的很慢。选择一个能够提供良好开发环境的技术,而不是去对着不友好的工具进行抱怨(降低开发的士气)。
-

谁是背后的应用程序
通过波兰的软件公司Octivi设计的平台。 我们专心于可伸缩的结构体系,把焦点集中于性能和实用性。我们还要致谢来自客户端侧的IT部门。
相关文章
-
推到极致 - Symfony2满足高性能需求 - Symfony2软件架构的细节特点描述
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































