
SQL开发中容易忽视的一些小地方( 三)
目的:这篇文章我想说说我在工作中关于in和union all 的用法.
索引定义
: 微软的SQL SERVER提供了两种索引:聚集索引(clustered
index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。
SARG的定义:用于限制搜索的一个操作,因为它通常是指一个特定的匹配,一个值得范围内的匹配或者两个以上条件的AND连接。形式如下: 列名 操作符 <常数 或 变量>或<常数 或 变量> 操作符列名列名可以出现在操作符的一边,而常数或变量出现在操作符的另一边。
SARG的意义:如果一个阶段可以被用作一个扫描参数(SARG),那么就称之为可优化的,并且可以利用索引快速获得所需数据。
讨论问题:现在有些观点直接说in不符合SARG标准,故在查询中全产生全表扫描.
我的观点:这个观点在早期的数据库中可能是这样,起码SQL2005足以证明上面的说法是错误的.
案例:有一会员表(member),里面包含代理信息,其中代理号proxyID上创建有索引.数量量在百万以上。
查询SQL:
方法1: select 相关字段 from member where proxyID IN(‘ID1‘,‘ID2‘,.....)
方法2: select 相关字段 from member where proxyID=‘ID1‘
union all
select 相关字段 from member where proxyID=‘ID1‘
union all
...
如何比较:
第一:proxyID的数量比较多,我测试时输入了30个proxyID
下面是两种方法的执行计划图:
1:union all的执行计划图:由于图比较长,所有分成两部分显示。
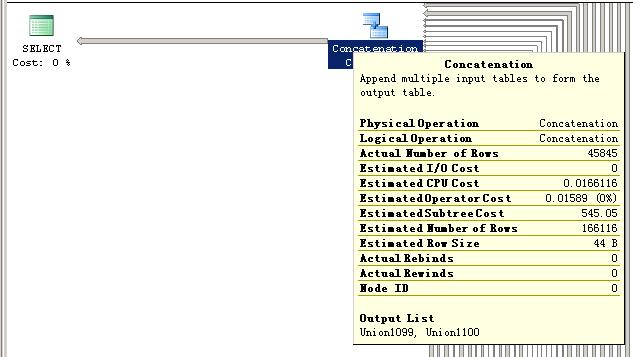
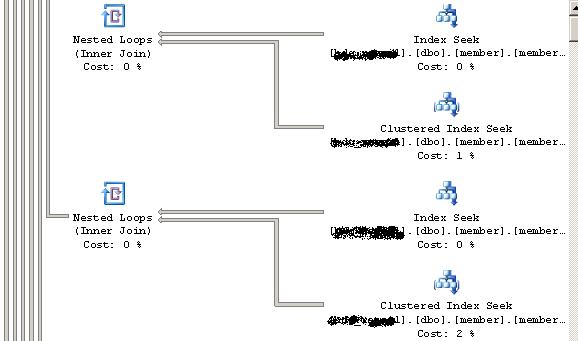
2:in的执行计划图:

1:无论哪种方法,都会用上索引.
2:两都的执行计划不同:当proxyID的数量比较多时,用in会直接查找索引,并有过滤的操作.union all则是连接了 n 个嵌套查询.
3:代理号比较多时,union all的效率明显高于in
第二:proxyID的数量比较小,现在分别输入两个,6个,15个,执行计划图可以看出,当proxyID的数量为15时,直接查找索引,而2个和6个时都选择嵌套查询来完成.因为union
all的执行计划图总是一样的,所有贴于不同proxyID下,用in查询的执行计划图:
1:两个代理的执行计划图: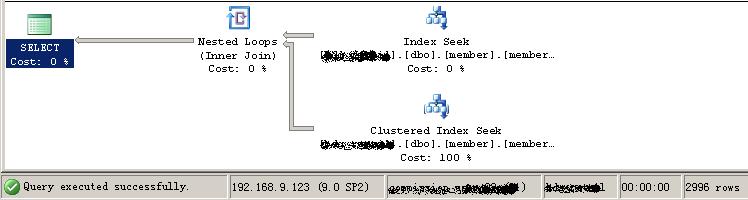
2:六个代理的执行计划图:
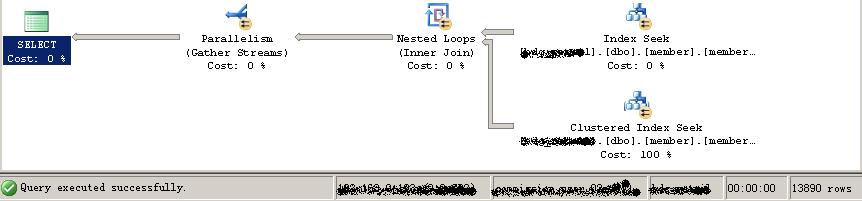
3:十五个代理的执行计划图:

1:无论哪种方法,都会用上索引.
2:proxyID的数据量比较小的时候在执行时间上和union all差距不大.
3:in里面的数据个数不同时,执行计划也会相应的同,数据量小时会采用嵌套查询,反之则直接查询索引以及其它相关辅助操作。
结论:现在的数据库引擎一般都会通过查询成本分析来选择最优的查询算法来执行,不能把以前的观点拿到现在说.in与union all的差别并不是永远不变的,看什么情况而定.类似in的还有or,对于or,有观点也说不能应用索引,其实和in一样,高版本中的都会用上索引。
注:
本文引用:MSDN,网络相关资料
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































