
redis和ssdb读取性能对比
浏览数:88 /
时间:2015年06月12日
最近关注了一下ssdb,他的特点是基于文件存储系统所以它支撑量大的数据而不因为内存的限制受取约束.从官网的测试报告来看其性能也非常出色和redis相当,因此可以使用他代表redis来进行k-v数据业务的处理.想法总是美好的,不过现实中就可能非常骨感.
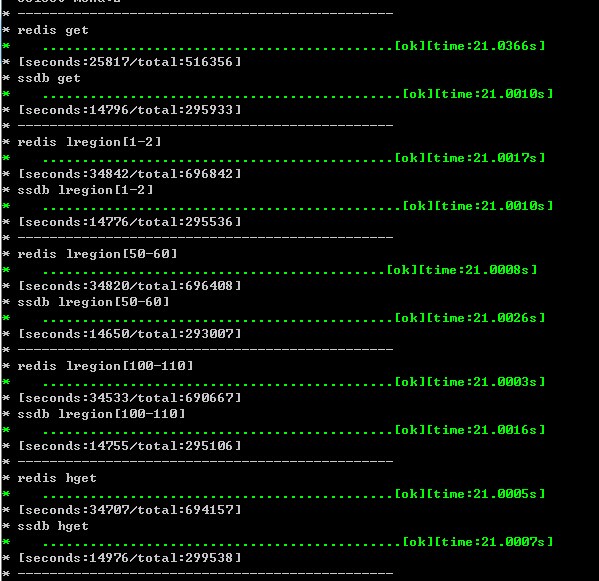
以于针对Redis和ssdb的几个读操进行一个简单的性能测试对比,这个测试不是直接在本机调用Redis和ssdb. 而是通过一个程序在别的服务器上调用.测试指令(get,hget,lregion)以下是测试结果截图
测试代码
private void HGetHandler(RedisClient e)
{
while (mRuning)
{
long index = System.Threading.Interlocked.Increment(ref mIndex);
ProtobufKey key = "user_" + Data.Import.Users[(int)(index % Data.Import.Users.Count)].Name;
key.Get<Model.Order, Model.Employee, Model.Customer>(e);
System.Threading.Interlocked.Increment(ref mCount);
}
}
private void LRegionHandler1TO2(RedisClient e)
{
while (mRuning)
{
ProtobufList<Model.Order> list = "Orders";
list.Range(1, 2, e);
System.Threading.Interlocked.Increment(ref mCount);
}
}
private void LRegionHandler50TO60(RedisClient e)
{
while (mRuning)
{
ProtobufList<Model.Order> list = "Orders";
list.Range(50, 60, e);
System.Threading.Interlocked.Increment(ref mCount);
}
}
private void LRegionHandler100TO110(RedisClient e)
{
while (mRuning)
{
ProtobufList<Model.Order> list = "Orders";
list.Range(100, 110, e);
System.Threading.Interlocked.Increment(ref mCount);
}
}
private void GetHandler(RedisClient e)
{
while (mRuning)
{
long index = System.Threading.Interlocked.Increment(ref mIndex);
ProtobufKey key = "user_" + Data.Import.Users[(int)(index % Data.Import.Users.Count)].Name;
key.Get<Model.User>(e);
System.Threading.Interlocked.Increment(ref mCount);
}
}
从测试结果看来差距还是非常明显,并不象官网那样说得这么理想.虽然SSDB效率上不如REDIS,但其基于磁盘存储有着其最大的优势,毕竟很多业务数据远超过服务器内存的容量.
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































