
[翻译]:SQL死锁-阻塞
一般情况下死锁不是一步到位的,它必须满足特定的条件,然后形成资源的循环依赖才会产生死锁,死锁之前一定会出现阻塞,由阻塞升级才有可能出现死锁,所以我们有必要了解系统中都有哪些已经被阻塞的锁。
我在解决共享锁产生的死锁时,我测试团队的一位同事的问题:既然所有的查询都已经是read uncommitted模式了,为什么还会有死锁呢?下面这篇会回答这个问题。
We already know what are the most important lock types and how transaction isolation levels affect locking behavior. Enough theory – today I’d like to show you simple example why blocking typically occurs in the system.
我们已经知道了最重要的几种锁的类型以及事务隔离级别是如何影响锁行为的。今天我将给大家讲一个例子,展示阻塞是如何发生的。
First, let’s create the table and populate it with the data.
首先,我们创建一个表格以及往这个表格中插入一定的测试数据。
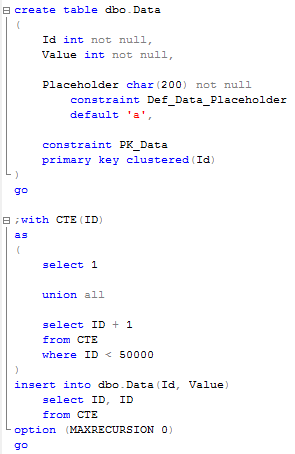
As you can see, this table has 50,000 rows now and 1 clustered index on ID column. Now let’s start another session and run update statement that acquires the lock (update row with ID = Value = 40000). I’m using read committed isolation level but that behavior occurs in any pessimistic isolation level (read uncommitted, read committed, repeatable read and serializable).
这个表格已经有50,000行数据,在Id列上有一个聚集索引。我们另起一个会话用来更新数据。注意,这个更新的事务未提交。
Next, let’s take a look at the list of the locks in the system with sys.dm_tran_locks DMV. I don’t have any other activity in the system but in your case, you can filter results by request_session_id if needed.
下一步,我们从sys.dm_tran_locks中查询所有的锁信息。这个视图由于统计了所有会话的锁信息,如果你查询的一个正在使用中的数据库。,那么显示的信息可能会比较多,你需要根据自己的会话Id过滤下数据结果,我本地因为没有其它的会话,所以不需要过滤。


So we can see 3 active locks: exclusive lock on key (row) level and 2 intent-exclusive locks on the page and table levels.
我们看到了3个锁信息,一个排它锁在行记录上,两个意向排它锁在页级以及数据表对象上。
Now let’s open another session and run select with filter on ID column in the read committed isolation level (you’ll experience the same behavior in repeatable read and serializable isolation levels). This select executes just fine with clustered index seek in the plan.
现在我们打开另外一个会话,在Read comitted 模式下执行一条按Id过滤的查询语句。这条查询语句在聚集索引查找下很顺利的执行成功。

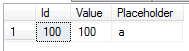

Now let’s change select and replace filter on ID column with filter on Value column. This select should return the same 1 row but it you run it, it would be blocked.
现在,我们更换查询条件,从Id转换成非聚集索引列Value ,这条语句应该返回一行数据,但当你执行时,它将会被阻塞住。![]()
If we query sys.dm_tran_locks again, we can see that the second session is waiting to acquire shared lock.

Let’s terminate the select and take a look at estimated execution plan.
让我们来看一看实时的执行计划

As you can see, the plan changes to clustered index scan. We know that this select returns only 1 row from the table but in order to process the request, SQL Server has to read every row from the table. When it tries to read updated row that held exclusive lock, the process would be blocked (S lock is incompatible with X/IX locks). That’s it – blocking occurs not because multiple sessions are trying to update the same data, but because of non-optimized query that needs to process/acquire lock on the data it does not really need.
就像你看到的,执行计划已经变为聚集索引扫描了。我们知道这个查询只应该返回一条数据,但SQL SERVER为了返回正确的行不得不读取所有行记录。当它尝试读取正在被更新的(已经被上了排它锁)数据行时就会出现阻塞。所以阻塞的发生并不是因为同时有多个会议尝试去更新相同的数据,而是因为没有经过优化的查询申请了锁,但读取到的数据往往是不必要的数据。
Now let’s try to run the same select in read uncommitted mode.
现在,我们在read uncommitted模式下执行相同的语句

As you can see – select runs just fine even with scan. As I already mentioned, in read uncommitted mode, readers don’t acquire shared locks. But let’s run update statement.
如图显示,查询语句在uncommitted模式式正常返回。就像我已经提醒过的,在read
uncommitted模式下,读取数据不需要申请共享锁,但我们来试试数据更新![]()
It would be blocked. If you take a look at the lock list, you’ll see that there is the wait on update lock (SQL Server acquires update locks when searches for the data for update)
阻塞出现,我们再看一下锁列表,将会发现一个更新锁,当前的状态为等待。

And this is the typical source of confusions – read uncommitted mode does not eliminate blocking – shared locks are not acquired, but update and exclusive locks are still in the game. So if you downgraded transaction isolation level to read uncommitted, you would not completely solve the blocking issues. In addition to that, you would introduce the bunch of consistency issues. The right way to achieve the goal is to illuminate the source of the problem – non-optimized queries.
这是典型的容易引起混淆的原因所在。read uncommitted模式并不会消除阻塞。共享锁虽然不需要申请了,但更新锁以及排它锁仍然存在。如果你将事务隔离级别降低到read uncommitted,你并不能完全解决阻塞的问题。额外说一下,这样会产生数据不致的问题。正确解决阻塞的方法是说明问题的根源:未经优化的查询。
Next time we will talk how to detect such queries.
下一次我们将讨论如何发现这些未经优化的查询。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































