
MySQL5.6.7-rc index condition pushdown 索引条件下推代码解读
MySQL5.6.7-rc index condition pushdown 索引条件下推代码解读
http://jishu.zol.com.cn/4505.html
对index condition pushdown很感兴趣,并且跟踪代码让自己受益良多,因此就来跟一下相关代码。
看的是mysql5.6.7-rc官方社区版。
先说说我对研究MySQL源码的看法:
每个使用MySQL数据库的人都应该看代码吗?不是的,那意味着MySQL数据库的使用门槛太高,几乎不可用;但另一方面,如果看MySQL代码的人多了,意味着有更多的人对MySQL数据库的了解更加深入。能够进一步推动MySQL数据库广泛而恰当地使用,为使用者、相关从业者创造更多的赢利机会和就业机会。
下面进入正题。
1. 单一字段索引
mysql> show create table pushdown\G
*************************** 1. row ***************************
Table: pushdown
Create Table: CREATE TABLE `pushdown` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`info` varchar(200) DEFAULT NULL,
`other` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=718829 DEFAULT CHARSET=latin1
1 row in set (0.08 sec)
mysql> select count(*) from pushdown;
| count(*) |
| 524288 |
mysql> explain select * from pushdown where name=’name6011′;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | pushdown | ref | name | name | 103 | const | 128 | Using index condition |
mysql> explain select * from pushdown where name=’name6011′ and info like ‘%1′;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | pushdown | ref | name | name | 103 | const | 128 | Using index condition; Using where |
Using where的意思是从存储引擎取得数据以后,还要再和条件进行匹配。本例就是与like ‘%1’进行匹配。
通过secondary index name查到name=’name6011’的主键;
再通过主键的值在cluster index中查出*(全部数据);
在用like ‘%1’把这些数据库不满足条件的过滤掉;
如果我们去比较5.1版本中的using where,发现using where会在我们以为不该出现的时候也出现。即我们以为通过索引已经找到了满足所有条件的数据,但还是能看到using where。这个问题似乎在5.6版本里解决了。
2. 两个字段联合索引
mysql> alter table pushdown drop key name;
Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table pushdown add key name_info(name,info);
Query OK, 0 rows affected (1 min 1.80 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table pushdown\G
*************************** 1. row ***************************
Table: pushdown
Create Table: CREATE TABLE `pushdown` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`info` varchar(200) DEFAULT NULL,
`other` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_info` (`name`,`info`)
) ENGINE=InnoDB AUTO_INCREMENT=718829 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
explain select * from pushdown where name=’name6011′;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | pushdown | ref | name_info | name_info | 103 | const | 128 | Using index condition |
只以name为条件查询,执行计划没有变化
explain select * from pushdown where name=’name6011′ and info like ‘%1′;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | pushdown | ref | name_info | name_info | 103 | const | 128 | Using index condition |
用两个条件查,比只在name上建索引时少了using where。这说明在利用secondary index name_info查到满足name=’name6011’的索引KEY时,又使用了like ‘%1’,也在索引name_info中查找,把不满足条件的记录过滤掉了。然后再利用索引name_info中得到的主键去cluster index查全部数据。
这是依据执行计划和以前看过5.1版本的代码来推测的。
下面跟代码找真相。
一路跟下去,找到比较where条件的位置。先把call stack记下来备查:
> mysqld.exe!Arg_comparator::compare_string() 行1374 C++
mysqld.exe!Arg_comparator::compare() 行84 + 0x1c 字节 C++
mysqld.exe!Item_func_eq::val_int() 行2198 + 0xe 字节 C++
mysqld.exe!Item::val_bool() 行203 + 0xf 字节 C++
mysqld.exe!Item_cond_and::val_int() 行5084 + 0xf 字节 C++
mysqld.exe!innobase_index_cond(void * file=0x0ef9b678) 行16388 + 0x2e 字节 C++
mysqld.exe!row_search_idx_cond_check(unsigned char * mysql_rec=0x0ef9d0a0, row_prebuilt_t * prebuilt=0x0efb11e0, const unsigned char * rec=0x06d3eab7, const unsigned long * offsets=0x11c9cf74) 行3604 + 0xf 字节 C++
mysqld.exe!row_search_for_mysql(unsigned char * buf=0x0ef9d0a0, unsigned long mode=2, row_prebuilt_t * prebuilt=0x0efb11e0, unsigned long match_mode=1, unsigned long direction=0) 行4678 + 0×18 字节 C++
mysqld.exe!ha_innobase::index_read(unsigned char * buf=0x0ef9d0a0, const unsigned char * key_ptr=0x0efb2560, unsigned int key_len=103, ha_rkey_function find_flag=HA_READ_KEY_EXACT) 行7438 + 0x1d 字节 C++
mysqld.exe!handler::index_read_map(unsigned char * buf=0x0ef9d0a0, const unsigned char * key=0x0efb2560, unsigned long keypart_map=1, ha_rkey_function find_flag=HA_READ_KEY_EXACT) 行2174 + 0×22 字节 C++
mysqld.exe!handler::ha_index_read_map(unsigned char * buf=0x0ef9d0a0, const unsigned char * key=0x0efb2560, unsigned long keypart_map=1, ha_rkey_function find_flag=HA_READ_KEY_EXACT) 行2669 + 0×70 字节 C++
mysqld.exe!join_read_always_key(st_join_table * tab=0x0efb2354) 行2185 + 0×32 字节 C++
mysqld.exe!sub_select(JOIN * join=0x0ef96d00, st_join_table * join_tab=0x0efb2354, bool end_of_records=false) 行1239 + 0xe 字节 C++
mysqld.exe!do_select(JOIN * join=0x0ef96d00) 行932 + 0×17 字节 C++
mysqld.exe!JOIN::exec() 行191 + 0×9 字节 C++
mysqld.exe!mysql_execute_select(THD * thd=0x057c1090, st_select_lex * select_lex=0x057c2bd8, bool free_join=true) 行1086 C++
mysqld.exe!mysql_select(THD * thd=0x057c1090, TABLE_LIST * tables=0x0ef96260, unsigned int wild_num=1, List<Item> & fields={…}, Item * conds=0x0ef96ba0, SQL_I_List<st_order> * order=0x057c2cd0, SQL_I_List<st_order> * group=0x057c2c6c, Item * having=0×00000000, unsigned __int64 select_options=2147748608, select_result * result=0x0ef96ce0, st_select_lex_unit * unit=0x057c2760, st_select_lex * select_lex=0x057c2bd8) 行1204 + 0×23 字节 C++
mysqld.exe!handle_select(THD * thd=0x057c1090, select_result * result=0x0ef96ce0, unsigned long setup_tables_done_option=0) 行110 + 0×78 字节 C++
mysqld.exe!execute_sqlcom_select(THD * thd=0x057c1090, TABLE_LIST * all_tables=0x0ef96260) 行4990 + 0xf 字节 C++
mysqld.exe!mysql_execute_command(THD * thd=0x057c1090) 行2554 + 0xd 字节 C++
mysqld.exe!mysql_parse(THD * thd=0x057c1090, char * rawbuf=0x0ef96080, unsigned int length=63, Parser_state * parser_state=0x11c9f840) 行6094 + 0×9 字节 C++
mysqld.exe!dispatch_command(enum_server_command command=COM_QUERY, THD * thd=0x057c1090, char * packet=0x0ef8dd91, unsigned int packet_length=63) 行1314 + 0×28 字节 C++
mysqld.exe!do_command(THD * thd=0x057c1090) 行1038 + 0x1b 字节 C++
mysqld.exe!do_handle_one_connection(THD * thd_arg=0x057c1090) 行969 + 0×9 字节 C++
mysqld.exe!handle_one_connection(void * arg=0x057c1090) 行885 + 0×9 字节 C++
mysqld.exe!pfs_spawn_thread(void * arg=0x0edb4ba0) 行1853 + 0×9 字节 C++
mysqld.exe!pthread_start(void * p=0x0edbbd10) 行61 + 0×9 字节 C
mysqld.exe!_callthreadstartex() 行348 + 0xf 字节 C
mysqld.exe!_threadstartex(void * ptd=0x0ef91dd8) 行331 C
kernel32.dll!75dded6c()
接下来看当前比较的是什么:
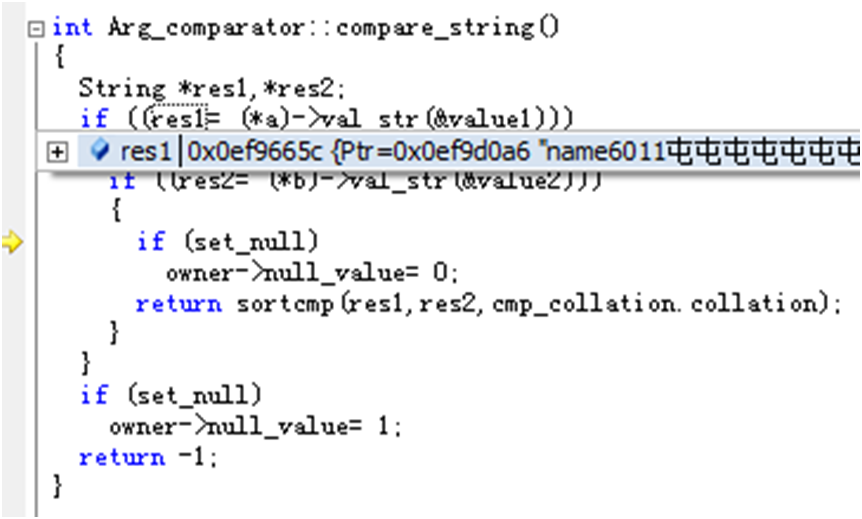
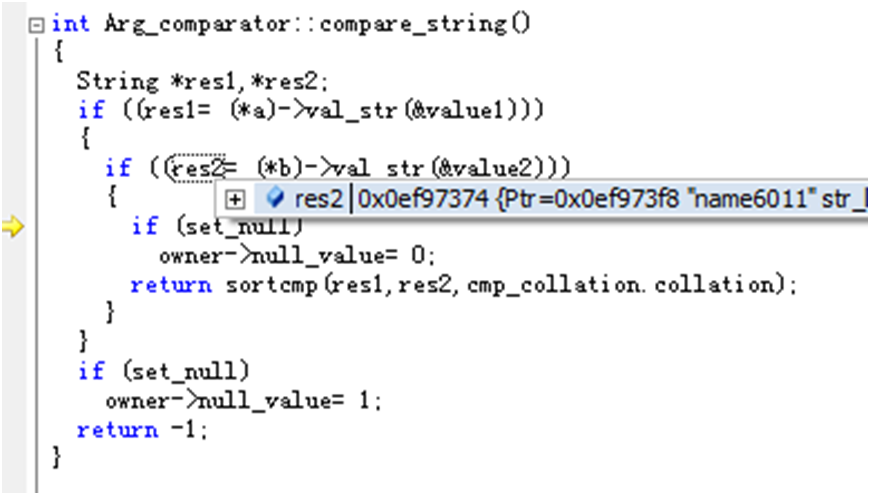
回到下面的循环中,再做后续的比较:
longlong Item_cond_and::val_int()
{
DBUG_ASSERT(fixed == 1);
List_iterator_fast<Item> li(list);
Item *item;
null_value= 0;
while ((item=li++))
{
if (!item->val_bool())
{
if (abort_on_null || !(null_value= item->null_value))
return 0; // return FALSE
}
}
return null_value ? 0 : 1;
}
再一路跟下去,进入like比较:
longlong Item_func_like::val_int()
{
DBUG_ASSERT(fixed == 1);
String* res = args[0]->val_str(&cmp.value1);
if (args[0]->null_value)
{
null_value=1;
return 0;
}
String* res2 = args[1]->val_str(&cmp.value2);
if (args[1]->null_value)
{
null_value=1;
return 0;
}
null_value=0;
if (canDoTurboBM)
return turboBM_matches(res->ptr(), res->length()) ? 1 : 0;
return my_wildcmp(cmp.cmp_collation.collation,
res->ptr(),res->ptr()+res->length(),
res2->ptr(),res2->ptr()+res2->length(),
escape,wild_one,wild_many) ? 0 : 1;
}
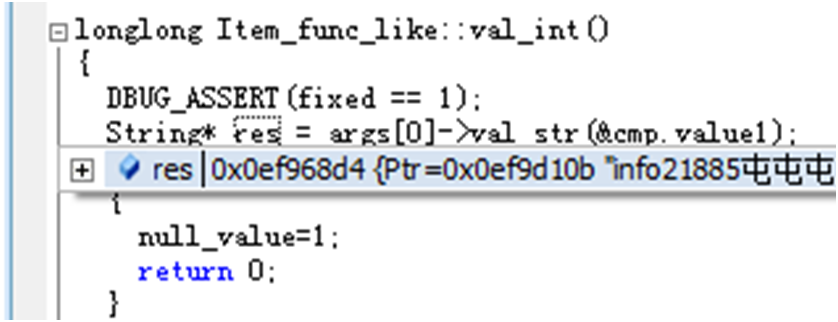
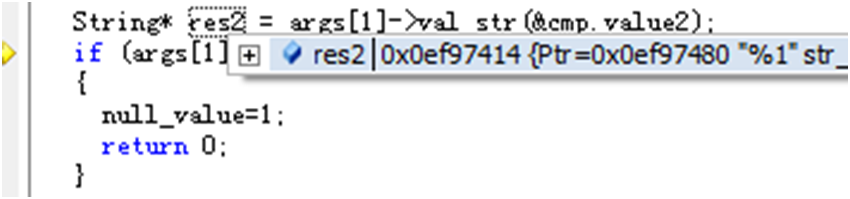
可以看到,一个是字段的值,一个是like后面的值。这一步info的值是info21885,不满足like ‘%1’,此记录就被过滤掉了。
当找到匹配的记录时,则还要从cluster index中读取数据,看代码
/* Check if the record matches the index condition. */
switch (row_search_idx_cond_check(buf, prebuilt, rec, offsets)) {
case ICP_NO_MATCH:
if (did_semi_consistent_read) {
row_unlock_for_mysql(prebuilt, TRUE);
}
goto next_rec;
case ICP_OUT_OF_RANGE:
err = DB_RECORD_NOT_FOUND;
goto idx_cond_failed;
case ICP_MATCH:
break;
}
/* Get the clustered index record if needed, if we did not do the
search using the clustered index. */
if (index != clust_index && prebuilt->need_to_access_clustered) {
requires_clust_rec:
ut_ad(index != clust_index);
/* We use a ‘goto’ to the preceding label if a consistent
read of a secondary index record requires us to look up old
versions of the associated clustered index record. */
ut_ad(rec_offs_validate(rec, index, offsets));
/* It was a non-clustered index and we must fetch also the
clustered index record */
mtr_has_extra_clust_latch = TRUE;
/* The following call returns ‘offsets’ associated with
‘clust_rec’. Note that ‘clust_rec’ can be an old version
built for a consistent read. */
err = row_sel_get_clust_rec_for_mysql(prebuilt, index, rec,
thr, &clust_rec,
&offsets, &heap, &mtr);
这个函数的名字很明确,get cluster record for mysql
函数说明:
/*********************************************************************//**
Retrieves the clustered index record corresponding to a record in a
non-clustered index. Does the necessary locking. Used in the MySQL
interface.
@return DB_SUCCESS, DB_SUCCESS_LOCKED_REC, or error code */
当ICP过滤的条件越多,需要从cluster index中读取的记录就越少。特别是当用到select *,特别是有blob、text字段时,从cluster index读取数据的代价就更为显著。
记得我们对like ‘%abc%’的优化吗?特别是表里有大字段的时候。可能会这样来优化:
select * from a,(select id from a where c1 like ‘%abc%’) b where a.id=b.id;
如果实际的SQL还需要一个等于的条件,比如c2=’ccc’。那么就可以这样优化:
建立索引c2_c1(c2,c1);
select * from a where c2=’ccc’ and c1 like ‘%abc%’;
SQL并不用改写,而ICP会使用c2_c1过滤掉所有不满足条件的记录,只有满足条件的才会去读cluster_index,这和以前我们优化成derived table的思路是一样的。
请大家尝试,并把结果反馈给我,感激不尽。注意这是5.6才有的特性。
3. 回过头来再看只在name一字段上建立索引的情况
mysql> explain select * from pushdown where name=’name6011′ and info like ‘%1′;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | pushdown | ref | name | name | 103 | const | 128 | Using index condition; Using where |
这时候有using where。Using where是什么呢?看一下代码:
static enum_nested_loop_state
evaluate_join_record(JOIN *join, JOIN_TAB *join_tab)
{
bool not_used_in_distinct=join_tab->not_used_in_distinct;
ha_rows found_records=join->found_records;
Item *condition= join_tab->condition();
bool found= TRUE;
DBUG_ENTER(“evaluate_join_record”);
DBUG_PRINT(“enter”,
(“join: %p join_tab index: %d table: %s cond: %p”,
join, static_cast<int>(join_tab - join_tab->join->join_tab),
join_tab->table->alias, condition));
/*就是这里了,当condition有值时就是using where了。
上面的例子,如果没有ICP支持,like ‘%1’就会在这里出现。
同样,当把索引改为只在name上时,like ‘%1’就在这里出现了。
*/
if (condition)
{
found= test(condition->val_int());//这里在检测where条件是否匹配了
if (join->thd->killed)
{
join->thd->send_kill_message();
DBUG_RETURN(NESTED_LOOP_KILLED);
}
/* check for errors evaluating the condition */
if (join->thd->is_error())
DBUG_RETURN(NESTED_LOOP_ERROR);
}

两个比较的项,前者是info字段,后者是’%1’。
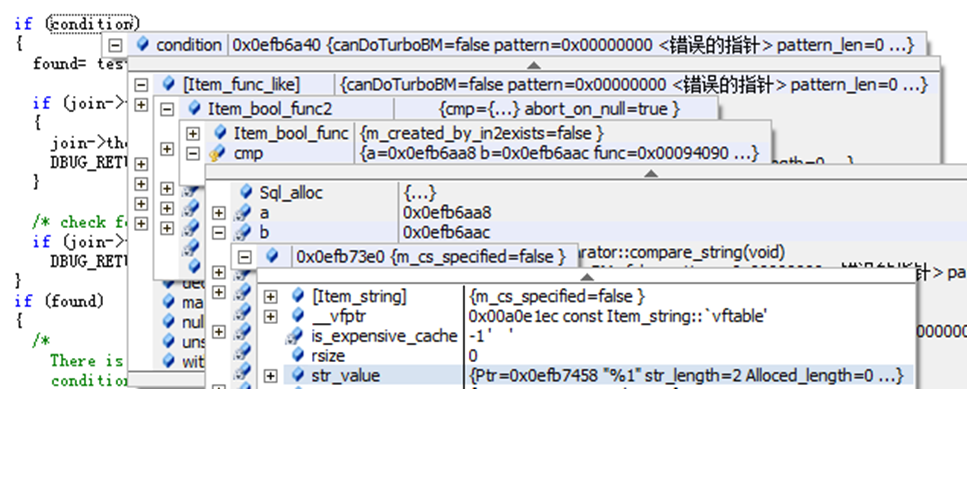

str_value里看到like条件’%1’
4. 在组内交流了一下,同学们给了很大帮助,提了非常有启发的问题:
两个字段模糊查询,能否用ICP?
除了模糊查询以后,函数能否用上ICP?
3个字段联合索引,第1和第3个字段有where条件,能否用上ICP?
mysql> select * from pushdown where name=’name658′ and info like ‘%6′;
+——-+———+———-+——-+
id | name | info | other |
+——-+———+———-+——-+
12266 | name658 | info12266 | NULL |
3056 | name658 | info3056 | NULL |
+——-+———+———-+——-+
2 rows in set (0.01 sec)
mysql> explain select * from pushdown where name=’name658′ and length(info)=8;
+—-+————-+———-+——+—————+———-+———+——-+——+———————-+
id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+———-+——+—————+———-+———+——-+——+———————-+
1 | SIMPLE | pushdown | ref | name_info | name_info | 53 | const | 4 | Using index condition |
+—-+————-+———-+——+—————+———-+———+——-+——+———————-+
1 row in set (0.02 sec)
mysql> show create table pushdown\G
*************************** 1. row ***************************
Table: pushdown
Create Table: CREATE TABLE `pushdown` (
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































