
SQL 语句及关键字的用法
一、SELECT

select [ALL|DISTINCT] select_list [into new table] FROM table_source [where serch_conditaion] [GROUP BY group_by_expression] [Having serch_conditaion] [Order by order_expression[ASC|DESC]] --从上面的语句可以看出SELECT 查询语句共有5个子句 其中SELECT\FROM 为必选语句 --SELECT 子句:用来指定由查询返回的列 --ALL|DISTINCT:用来指定对查询结果集,相同行的处理方式,ALL-为所有 DISTINCT:保留一条记录 --select_list:用来显示要显示的目标列,全部可以用 * 代替,不是全部每个列字段用,分割 --into new table:用来创建一个新的临时表 --FROM table_source:指定查询的数据源 --where serch_conditaion:用来限定返回行的搜索条件 --GROUP BY group_by_expression]:用来指定查到结果的分组条件 --Having serch_conditaion:用来指定组成或聚合的搜索条件 --Order by order_expression[ASC|DESC]:用来指定结果集的排序方式
二、PIVOT 行转列
注意:PIVOT、UNPIVOT是SQL Server 2005 的语法,使用需修改数据库兼容级别
在数据库属性->选项->兼容级别改为 90
PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现
PIVOT的一般语法是:PIVOT(聚合函数(列) FOR 列 in (…) )AS P
完整语法:
table_source --数据源
PIVOT(
聚合函数(value_column) --统计转化行值的聚合函数值
FOR pivot_column --需要转化的行列名
IN(<column_list>) --行值得结合
)
典型实例:
1、建立表格 ifobject_id(‘tb‘)isnotnulldroptabletb go create table tb (姓名varchar(10),课程varchar(10),分数int) insert into tb values (‘张三‘,‘语文‘,74) insert into tb values (‘张三‘,‘数学‘,83) insert into tb values (‘张三‘,‘物理‘,93) insertintotbvalues (‘李四‘,‘语文‘,74) insert into tb values (‘李四‘,‘数学‘,84) insert into tb values (‘李四‘,‘物理‘,94) go select * from tb go 姓名 课程 分数 ---------- ---------- ----------- 张三 语文 74 张三 数学 83 张三 物理 93 李四 语文 74 李四 数学 84 李四 物理 94 2、使用SQL Server 2000静态SQL --c select姓名, max(case 课程 when ‘语文‘ then 分数 else 0 end)语文, max(case 课程 when ‘数学‘ then 分数 else 0 end)数学, max(case 课程 when ‘物理‘ then 分数 else 0 end)物理 from tb group by 姓名 姓名 语文 数学 物理 ---------- ----------- ----------- ----------- 李四 74 84 94 张三 74 83 93 3、使用SQL Server 2005静态SQL select*fromtb pivot(max(分数)for课程in(语文,数学,物理))a
三、
UNPIVOT用于将列明转为列值(即列转行),在SQL Server 2000可以用UNION来实现
完整语法:
table_source --数据源 转化后的表结构查询 例如:select 姓名,课程,分数 from tb1
UNPIVOT(
value_column --列值(本身列名的值 如:语文 列 值 83 ) 例如:分数
FOR pivot_column --列名 (集合列转成行后的名字 例如:课程)
IN(<column_list>) --集合参数 (例如:[语文],[数学],[物理])
)
示例:
create table tb(姓名varchar(10),语文int,数学int,物理int) insert into tb values(‘张三‘,74,83,93) insert into tb values(‘李四‘,74,84,94) go select *from tb go 姓名 语文 数学 物理 ---------- ----------- ----------- ----------- 张三 74 83 93 李四 74 84 94 2、使用SQL Server 2000静态SQL --SQL SERVER 2000静态SQL。 select*from ( select 姓名,课程=‘语文‘,分数=语文 from tb union all select姓名,课程=‘数学‘,分数=数学 from tb union all select姓名,课程=‘物理‘,分数=物理 from tb ) t order b y 姓名,case 课程 when ‘语文‘ then 1 when ‘数学‘ then 2 when ‘物理‘ then 3 end 姓名 课程 分数 ---------- ---- ----------- 李四 语文 74 李四 数学 84 李四 物理 94 张三 语文 74 张三 数学 83 张三 物理 93 2、使用SQL Server 2005静态SQL --SQL SERVER 2005动态SQL select 姓名,课程,分数 from tb unpivot ( 分数 for 课程 in([语文],[数学],[物理])) t
四、 merge 用于2张表更新的常用关键字
基本语法:
MERGE table --要匹配的目标表 a
using scourtb --查询的源数据或者元数据表名 b
on conditaion --元数据与目标表的匹配条件whenmatchedthen --匹配成功updateseta.字段=X --一般匹配成功都是执行更新whennotmatchedthen --匹配不成功insert(A字段)values(对应的值); --执行插入 向目标表插入元数据的新数据
WHEN NOT MATCHED BY SOURCE THEN DELETE; -- 目标表有,源表没有,目标表该数据删除.
示例:
create table employee ( empid integer, fname nvarchar(20), lname nvarchar(20) ) insert into employee select 2021110,‘小‘,‘张‘ insert into employee select 2021110,‘小‘,‘李‘ create table test ( id integer, num integer ) insert into test select 2021110,2 insert into test select 2,2 期望结果语句:select * from employee 2021110,‘大‘,‘张‘ 2021110,‘大‘,‘李‘ 2,‘大‘,‘大‘
SQL语句实现:
merge into employee a
using test b
on b.id = a.empid
when matched then
update set a.fname= ‘大‘
when not matched then
insert values (id,‘大‘,‘大‘);
end
exec test_merge
select * from employee
/*
empid fname lname
----------- -------------------- --------------------
2021110 大 张
2021110 大 李
2 大 大
(3 行受影响)
1、作用
删除指定长度的字符,并在指定的起点处插入另一组字符。
2、语法
STUFF ( character_expression , start , length ,character_expression )
3、示例
以下示例在第一个字符串 abcdef 中删除从第 2 个位置(字符 b)开始的三个字符,然后在删除的起始位置插入第二个字符串,从而创建并返回一个字符串
SELECT STUFF(‘abcdef‘, 2, 3, ‘ijklmn‘)
GO
下面是结果集
aijklmnef
4、参数
character_expression
一个字符数据表达式。character_expression 可以是常量、变量,也可以是字符列或二进制数据列。
start
一个整数值,指定删除和插入的开始位置。如果 start 或 length 为负,则返回空字符串。如果 start 比第一个 character_expression长,则返回空字符串。start 可以是 bigint 类型。
length
一个整数,指定要删除的字符数。如果 length 比第一个 character_expression长,则最多删除到最后一个 character_expression 中的最后一个字符。length 可以是 bigint 类型。
5、返回类型
如果 character_expression 是受支持的字符数据类型,则返回字符数据。如果 character_expression 是一个受支持的 binary 数据类型,则返回二进制数据。
6、备注
如果结果值大于返回类型支持的最大值,则产生错误。
一.FOR XML PATH 简单介绍
那么还是首先来介绍一下FOR XML PATH ,假设现在有一张兴趣爱好表(hobby)用来存放兴趣爱好,表结构如下:
接下来我们来看应用FOR XML PATH的查询结果语句如下:
结果:
<hobbyID>1</hobbyID>
<hName>爬山</hName>
</row>
<row>
<hobbyID>2</hobbyID>
<hName>游泳</hName>
</row>
<row>
<hobbyID>3</hobbyID>
<hName>美食</hName>
</row>
由此可见FOR XML PATH 可以将查询结果根据行输出成XML各式!
那么,如何改变XML行节点的名称呢?代码如下:
结果一定也可想而知了吧?没错原来的行节点<row> 变成了我们在PATH后面括号()中,自定义的名称<MyHobby>,结果如下:
<hobbyID>1</hobbyID>
<hName>爬山</hName>
</MyHobby>
<MyHobby>
<hobbyID>2</hobbyID>
<hName>游泳</hName>
</MyHobby>
<MyHobby>
<hobbyID>3</hobbyID>
<hName>美食</hName>
</MyHobby>
这个时候细心的朋友一定又会问那么列节点如何改变呢?还记的给列起别名的关键字AS吗?对了就是用它!代码如下:
那么这个时候我们列的节点名称也会编程我们自定义的名称 <MyCode>与<MyName>结果如下:
<MyCode>1</MyCode>
<MyName>爬山</MyName>
</MyHobby>
<MyHobby>
<MyCode>2</MyCode>
<MyName>游泳</MyName>
</MyHobby>
<MyHobby>
<MyCode>3</MyCode>
<MyName>美食</MyName>
</MyHobby>
噢! 既然行的节点与列的节点我们都可以自定义,我们是否可以构建我们喜欢的输出方式呢?还是看代码:
没错我们还可以通过符号+号,来对字符串类型字段的输出格式进行定义。结果如下:
那么其他类型的列怎么自定义? 没关系,我们将它们转换成字符串类型就行啦!例如:
好的 FOR XML PATH就基本介绍到这里吧,更多关于FOR XML的知识请查阅帮助文档!
接下来我们来看一个FOR XML PATH的应用场景吧!那么开始吧。。。。。。
二.一个应用场景与FOR XML PATH应用
首先呢!我们在增加一张学生表,列分别为(stuID,sName,hobby),stuID代表学生编号,sName代表学生姓名,hobby列存学生的爱好!那么现在表结构如下:

这时,我们的要求是查询学生表,显示所有学生的爱好的结果集,代码如下:
SELECT sName,
(SELECT hobby+‘,‘ FROM student
WHERE sName=A.sName
FOR XML PATH(‘‘)) AS StuList
FROM student A
GROUP BY sName
) B
结果如下: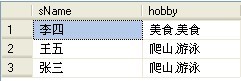
分析: 好的,那么我们来分析一下,首先看这句:
WHERE sName=A.sName
FOR XML PATH(‘‘)
这句是通过FOR XML PATH 将某一姓名如张三的爱好,显示成格式为:“ 爱好1,爱好2,爱好3,”的格式!
那么接着看:
SELECT sName,
(SELECT hobby+‘,‘ FROM student
WHERE sName=A.sName
FOR XML PATH(‘‘)) AS StuList
FROM student A
GROUP BY sName
) B
剩下的代码首先是将表分组,在执行FOR XML PATH 格式化,这时当还没有执行最外层的SELECT时查询出的结构为:

可以看到StuList列里面的数据都会多出一个逗号,这时随外层的语句:SELECT B.sName,LEFT(StuList,LEN(StuList)-1) as hobby 就是来去掉逗号,并赋予有意义的列明!
也可以这样写:
select NAME,
STUFF((select ‘,‘+fv+‘‘ from #TEMP tb1 where tb1.name=tb.name for xml path(‘‘)),1,1,‘‘) as fv --截取查询的结果集合,替换第一个字符
from #TEMP as tb group by tb.NAME
三、关于主从表关联取从表最大数据一条记录问题
select a.*,b.* FROM dbo.SQ_AJBL AS a
left join SQ_AJBLWorkFlow AS b on a.gID=b.gPID
where b.dCreateDate IN (select max(dCreateDate) from SQ_AJBLWorkFlow GROUP BY gPID)
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































