
Cassandra 分布式数据库详解,第 2 部分:数据结构与数据读写
Cassandra 的数据存储结构
Cassandra 中的数据主要分为三种:
- CommitLog:主要记录下客户端提交过来的数据以及操作。这个数据将被持久化到磁盘中,以便数据没有被持久化到磁盘时可以用来恢复。
- Memtable:用户写的数据在内存中的形式,它的对象结构在后面详细介绍。其实还有另外一种形式是 BinaryMemtable 这个格式目前 Cassandra 并没有使用,这里不再介绍了。
- SSTable:数据被持久化到磁盘,这又分为 Data、Index 和 Filter 三种数据格式。
CommitLog 数据格式
CommitLog 的数据只有一种,那就是按照一定格式组成 byte 组数,写到 IO 缓冲区中定时的被刷到磁盘中持久化,在上一篇的配置文件详解中已经有说到 CommitLog 的持久化方式有两种,一个是 Periodic 一个是 Batch,它们的数据格式都是一样的,只是前者是异步的,后者是同步的,数据被刷到磁盘的频繁度不一样。关于 CommitLog 的相关的类结构图如下:
图 1. CommitLog 的相关的类结构图

它持久化的策略也很简单,就是首先将用户提交的数据所在的对象 RowMutation 序列化成 byte 数组,然后把这个对象和 byte 数组传给 LogRecordAdder 对象,由 LogRecordAdder 对象调用 CommitLogSegment 的 write 方法去完成写操作,这个 write 方法的代码如下:
清单 1. CommitLogSegment. write
public CommitLogSegment.CommitLogContext write(RowMutation rowMutation,
Object serializedRow){
long currentPosition = -1L;
...
Checksum checkum = new CRC32();
if (serializedRow instanceof DataOutputBuffer){
DataOutputBuffer buffer = (DataOutputBuffer) serializedRow;
logWriter.writeLong(buffer.getLength());
logWriter.write(buffer.getData(), 0, buffer.getLength());
checkum.update(buffer.getData(), 0, buffer.getLength());
}
else{
assert serializedRow instanceof byte[];
byte[] bytes = (byte[]) serializedRow;
logWriter.writeLong(bytes.length);
logWriter.write(bytes);
checkum.update(bytes, 0, bytes.length);
}
logWriter.writeLong(checkum.getValue());
...
}
这个代码的主要作用就是如果当前这个根据 columnFamily 的 id 还没有被序列化过,将会根据这个 id 生成一个 CommitLogHeader 对象,记录下在当前的 CommitLog 文件中的位置,并将这个 header 序列化,覆盖以前的 header。这个 header 中可能包含多个没有被序列化到磁盘中的 RowMutation 对应的 columnFamily 的 id。如果已经存在,直接把 RowMutation 对象的序列化结果写到 CommitLog 的文件缓存区中后面再加一个 CRC32 校验码。Byte 数组的格式如下:
图 2. CommitLog 文件数组结构

上图中每个不同的 columnFamily 的 id 都包含在 header 中,这样做的目的是更容易的判断那些数据没有被序列化。
CommitLog 的作用是为恢复没有被写到磁盘中的数据,那如何根据 CommitLog 文件中存储的数据恢复呢?这段代码在 recover 方法中:
清单 2. CommitLog.recover
public static void recover(File[] clogs) throws IOException{
...
final CommitLogHeader clHeader = CommitLogHeader.readCommitLogHeader(reader);
int lowPos = CommitLogHeader.getLowestPosition(clHeader);
if (lowPos == 0) break;
reader.seek(lowPos);
while (!reader.isEOF()){
try{
bytes = new byte[(int) reader.readLong()];
reader.readFully(bytes);
claimedCRC32 = reader.readLong();
}
...
ByteArrayInputStream bufIn = new ByteArrayInputStream(bytes);
Checksum checksum = new CRC32();
checksum.update(bytes, 0, bytes.length);
if (claimedCRC32 != checksum.getValue()){continue;}
final RowMutation rm =
RowMutation.serializer().deserialize(new DataInputStream(bufIn));
}
...
}
这段代码的思路是:反序列化 CommitLog 文件的 header 为 CommitLogHeader 对象,寻找 header 对象中没有被回写的最小 RowMutation 位置,然后根据这个位置取出这个 RowMutation 对象的序列化数据,然后反序列化为 RowMutation 对象,然后取出 RowMutation 对象中的数据重新保存到 Memtable 中,而不是直接写到磁盘中。CommitLog 的操作过程可以用下图来清楚的表示:
图 3. CommitLog 数据格式的变化过程

Memtable 内存中数据结构
Memtable 内存中数据结构比较简单,一个 ColumnFamily 对应一个唯一的 Memtable 对象,所以 Memtable 主要就是维护一个 ConcurrentSkipListMap<DecoratedKey, ColumnFamily> 类型的数据结构,当一个新的 RowMutation 对象加进来时,Memtable 只要看看这个结构是否 <DecoratedKey, ColumnFamily> 集合已经存在,没有的话就加进来,有的话取出这个 Key 对应的 ColumnFamily,再把它们的 Column 合并。Memtable 相关的类结构图如下:
图 4. Memtable 相关的类结构图
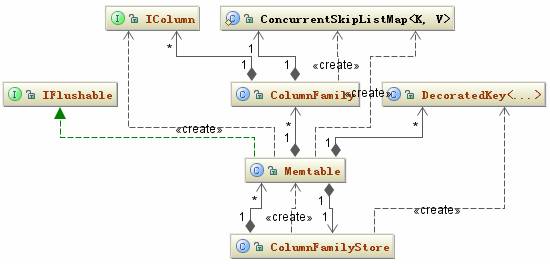
Memtable 中的数据会根据配置文件中的相应配置参数刷到本地磁盘中。这些参数在上一篇中已经做了详细说明。
前面已经多处提到了 Cassandra 的写的性能很好,好的原因就是因为 Cassandra 写到数据首先被写到 Memtable 中,而 Memtable 是内存中的数据结构,所以 Cassandra 的写是写内存的,下图基本上描述了一个 key/value 数据是怎么样写到 Cassandra 中的 Memtable 数据结构中的。
图 5. 数据被写到 Memtable

SSTable 数据格式
每添加一条数据到 Memtable 中,程序都会检查一下这个 Memtable 是否已经满足被写到磁盘的条件,如果条件满足这个 Memtable 就会写到磁盘中。先看一下这个过程涉及到的类。相关类图如图 6 所示:
图 6. SSTable 持久化类结构图
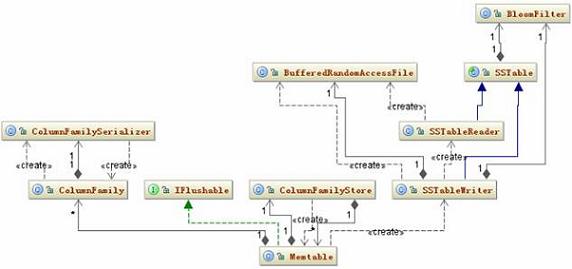
Memtable 的条件满足后,它会创建一个 SSTableWriter 对象,然后取出 Memtable 中所有的 <DecoratedKey, ColumnFamily> 集合,将 ColumnFamily 对象的序列化结构写到 DataOutputBuffer 中。接下去 SSTableWriter 根据 DecoratedKey 和 DataOutputBuffer 分别写到 Date、Index 和 Filter 三个文件中。
Data 文件格式如下:
图 7. SSTable 的 Data 文件结构

Data 文件就是按照上述 byte 数组来组织文件的,数据被写到 Data 文件中是接着就会往 Index 文件中写,Index 中到底写什么数据呢?
其实 Index 文件就是记录下所有 Key 和这个 Key 对应在 Data 文件中的启示地址,如图 8 所示:
图 8. Index 文件结构

Index 文件实际上就是 Key 的一个索引文件,目前只对 Key 做索引,对 super column 和 column 都没有建索引,所以要匹配 column 相对来说要比 Key 更慢。
Index 文件写完后接着写 Filter 文件,Filter 文件存的内容就是 BloomFilter 对象的序列化结果。它的文件结构如图 9 所示:
图 9. Filter 文件结构

BloomFilter 对象实际上对应一个 Hash 算法,这个算法能够快速的判断给定的某个 Key 在不在当前这个 SSTable 中,而且每个 SSTable 对应的 BloomFilter 对象都在内存中,Filter 文件指示 BloomFilter 持久化的一个副本。三个文件对应的数据格式可以用下图来清楚的表示:
图 10. SSTable 数据格式转化

这个三个文件写完后,还要做的一件事件就是更新前面提到的 CommitLog 文件,告诉 CommitLog 的 header 所存的当前 ColumnFamily 的没有写到磁盘的最小位置。
在 Memtable 往磁盘中写的过程中,这个 Memtable 被放到 memtablesPendingFlush 容器中,以保证在读时候它里面存的数据能被正确读到,这个在后面数据读取时还会介绍。
数据的写入
数据要写到 Cassandra 中有两个步骤:
- 找到应该保存这个数据的节点
- 往这个节点写数据。客户端写一条数据必须指定 Keyspace、ColumnFamily、Key、Column Name 和 Value,还可以指定 Timestamp,以及数据的安全等级。
数据写入涉及的主要相关类如下图所示:
图 11. Insert 相关类图

大慨的写入逻辑是这样的:
CassandraServer 接收到要写入的数据时,首先创建一个 RowMutation 对象,再创建一个 QueryPath 对象,这个对象中保存了 ColumnFamily、Column Name 或者 Super Column Name。接着把用户提交的所有数据保存在 RowMutation 对象的 Map<String, ColumnFamily> 结构中。接下去就是根据提交的 Key 计算集群中那个节点应该保存这条数据。这个计算的规则是:将 Key 转化成 Token,然后在整个集群的 Token 环中根据二分查找算法找到与给定的 Token 最接近的一个节点。如果用户指定了数据要保存多个备份,那么将会顺序在 Token 环中返回与备份数相等的节点。这是一个基本的节点列表,后面 Cassandra 会判断这些节点是否正常工作,如果不正常寻找替换节点。还有还要检查是否有节点正在启动,这种节点也是要在考虑的范围内,最终会形成一个目标节点列表。最后把数据发送到这些节点。
接下去就是将数据保存到 Memtable 中和 CommitLog 中,关于结果的返回根据用户指定的安全等级不同,可以是异步的,也可以是同步的。如果某个节点返回失败,将会再次发送数据。下图是当 Cassandra 接收到一条数据时到将数据写到 Memtable 中的时序图。
图 12. Insert 操作的时序图

数据的读取
Cassandra 的写的性能要好于读的性能,为何写的性能要比读好很多呢?原因是,Cassandra 的设计原则就是充分让写的速度更快、更方便而牺牲了读的性能。事实也的确如此,仅仅看 Cassandra 的数据的存储形式就能发现,首先是写到 Memtable 中,然后将 Memtable 中数据刷到磁盘中,而且都是顺序保存的不检查数据的唯一性,而且是只写不删(删除规则在后面介绍),最后才将顺序结构的多个 SSTable 文件合并。这每一步难道不是让 Cassandra 写的更快。这个设计想想对读会有什么影响。首先,数据结构的复杂性,Memtable 中和 SSTable 中数据结构肯定不同,但是返回给用户的肯定是一样的,这必然会要转化。其次,数据在多个文件中,要找的数据可能在 Memtable 中,也可能在某个 SSTable 中,如果有 10 个 SSTable,那么就要在到 10 个 SSTable 中每个找一遍,虽然使用了 BloomFilter 算法可以很快判断到底哪个 SSTable 中含有指定的 key。还有可能在 Memtable 到 SSTable 的转化过程中,这也是要检查一遍的,也就是数据有可能存在什么地方,就要到哪里去找一遍。还有找出来的数据可能是已经被删除的,但也没办法还是要取。
下面是读取数据的相关类图:
图 13. 读取相关类图

根据上面的类图读取的逻辑是,CassandraServer 创建 ReadCommand 对象,这个对象保存了用户要获取记录的所有必须指定的条件。然后交给 weakReadLocalCallable 这个线程去到 ColumnFamilyStore 对象中去搜索数据,包括 Memtable 和 SSTable。将找到的数据组装成 Row 返回,这样一个查询过程就结束了。这个查询逻辑可以用下面的时序图来表示:
图 14. 查询数据时序图

在上图中还一个地方要说明的是,取得 key 对应的 ColumnFamily 要至少在三个地方查询,第一个就是 Memtable 中,第二个是 MemtablesPendingFlush,这个是将 Memtable 转化为 SSTable 之前的一个临时 Memtable。第三个是 SSTable。在 SSTable 中查询最为复杂,它首先将要查询的 key 与每个 SSTable 所对应的 Filter 做比较,这个 Filter 保存了所有这个 SSTable 文件中含有的所有 key 的 Hash 值,这个 Hsah 算法能快速判断指定的 key 在不在这个 SSTable 中,这个 Filter 的值在全部保存在内存中,这样能快速判断要查询的 key 在那个 SSTable 中。接下去就要在 SSTable 所对应的 Index 中查询 key 所对应的位置,从前面的 Index 文件的存储结构知道,Index 中保存了具体数据在 Data 文件中的 Offset。,拿到这个 Offset 后就可以直接到 Data 文件中取出相应的长度的字节数据,反序列化就可以达到目标的 ColumnFamily。由于 Cassandra 的存储方式,同一个 key 所对应的值可能存在于多个 SSTable 中,所以直到查找完所有的 SSTable 文件后再与前面的两个 Memtable 查找出来的结果合并,最终才是要查询的值。
另外,前面所描述的是最坏的情况,也就是查询在完全没有缓存的情况下,当然 Cassandra 在对查询操作也提供了多级缓存。第一级直接针对查询结果做缓存,这个缓存的设置的配置项是 Keyspace 下面的 RowsCached。查询的时候首先会在这个 Cache 中找。第二级 Cache 对应 SSTable 的 Index 文件,它可以直接缓存要查询 key 所对应的索引。这个配置项同样在 Keyspace 下面的 KeysCached 中,如果这个 Cache 能命中,将会省去 Index 文件的一次 IO 查询。最后一级 Cache 是做磁盘文件与内存文件的 mmap,这种方式可以提高磁盘 IO 的操作效率,鉴于索引大小的限制,如果 Data 文件太大只能在 64 位机器上使用这个技术。
数据的删除
从前面的数据写入规则可以想象,Cassandra 要想删除数据是一件麻烦的事,为何这样说?理由如下:
- 数据有多处 同时还可能在多个节点都有保存。
- 数据的结构有多种 数据会写在 CommitLog 中、Memtable 中、SSTable 中,它们的数据结构都不一样。
- 数据时效性不一致 由于是集群,所以数据在节点之间传输必然有延时。
除了这三点之外还有其它一些难点如 SSTable 持久化数据是顺序存储的,如果删除中间一段,那数据有如何移动,这些问题都非常棘手,如果设计不合理,性能将会非常之差。
本部分将讨论 Cassandra 是如何解决这些问题的。
CassandraServer 中删除数据的接口只有一个 remove,下面是 remove 方法的源码:
清单 3. CassandraServer.remove
public void remove(String table, String key, ColumnPath column_path,
long timestamp, ConsistencyLevel consistency_level){
checkLoginDone();
ThriftValidation.validateKey(key);
ThriftValidation.validateColumnPathOrParent(table, column_path);
RowMutation rm = new RowMutation(table, key);
rm.delete(new QueryPath(column_path), timestamp);
doInsert(consistency_level, rm);
}
仔细和 insert 方法比较,发现只有一行不同:insert 方法调用的是 rm.add 而这里是 rm.delete。那么这个 rm.delete 又做了什么事情呢?下面是 delete 方法的源码:
清单 4. RowMutation. Delete
public void delete(QueryPath path, long timestamp){
...
if (columnFamily == null)
columnFamily = ColumnFamily.create(table_, cfName);
if (path.superColumnName == null && path.columnName == null){
columnFamily.delete(localDeleteTime, timestamp);
}else if (path.columnName == null){
SuperColumn sc = new SuperColumn(path.superColumnName,
DatabaseDescriptor.getSubComparator(table_, cfName));
sc.markForDeleteAt(localDeleteTime, timestamp);
columnFamily.addColumn(sc);
}else{
ByteBuffer bytes = ByteBuffer.allocate(4);
bytes.putInt(localDeleteTime);
columnFamily.addColumn(path, bytes.array(), timestamp, true);
}
}
这段代码的主要逻辑就是,如果是删除指定 Key 下的某个 Column,那么将这个 Key 所对应的 Column 的 vlaue 设置为当前系统时间,并将 Column 的 isMarkedForDelete 属性设置为 TRUE,如果是要删除这个 Key 下的所有 Column 则设置这个 ColumnFamily 的删除时间期限属性。然后将这个新增的一条数据按照 Insert 方法执行下去。
这个思路现在已经很明显了,它就是通过设置同一个 Key 下对应不同的数据来更新已经在 ConcurrentSkipListMap 集合中存在的数据。这种方法的确很好,它能够达到如下目的:
- 简化了数据的操作逻辑。将添加、修改和删除逻辑都统一起来。
- 解决了前面提到的三个难点。因为它就是按照数据产生的方式,来修改数据。有点以其人之道还治其人之身的意思。
但是这仍然有两个问题:这个只是修改了指定的数据,它并没有删除这条数据;还有就是 SSTable 是根据 Memtable 中的数据保存的,很可能会出现不同的 SSTable 中保存相同的数据,这个又怎么解决?的确如此,Cassandra 并没有删除你要删除的数据,Cassandra 只是在你查询数据返回之前,过滤掉 isMarkedForDelete 为 TRUE 的记录。它能够保证你删除的数据你不能再查到,至于什么时候真正删除,你就不需要关心了。Cassandra 删除数据的过程很复杂,真正删除数据是在 SSTable 被压缩的过程中,SSTable 压缩的目的就是把同一个 Key 下对应的数据都统一到一个 SSTable 文件中,这样就解决了同一条数据在多处的问题。压缩的过程中 Cassandra 会根据判断规则判定哪些数据应该被删除。
SSTable 的压缩
数据的压缩实际上是数据写入 Cassandra 的一个延伸,前面描述的数据写入和数据的读取都有一些限制,如:在写的过程中,数据会不停的将一定大小的 Memtable 刷到磁盘中,这样不停的刷,势必会产生很多的同样大小的 SSTable 文件,不可能这样无限下去。同样在读的过程中,如果太多的 SSTable 文件必然会影响读的效率,SSTable 越多就会越影响查询。还有一个 Key 对应的 Column 分散在多个 SSTable 同样也会是问题。还有我们知道 Cassandra 的删除同样也是一个写操作,同样要处理这些无效的数据。
鉴于以上问题,必然要对 SSTable 文件进行合并,合并的最终目的就是要将一个 Key 对应的所有 value 合并在一起。该组合的组合、该修改的修改,该删除的删除。然后将这个 Key 所对应的数据写在 SSTable 所对应的 Data 文件的一段连续的空间上。
何时压缩 SSTable 文件由 Cassandra 来控制,理想的 SSTable 文件个数在 4~32 个。当新增一个 SSTable 文件后 Cassandra 会计算当期的平均 SSTable 文件的大小当新增的 SSTable 大小在平均 SSTable 大小的 0.5~1.5 倍时 Cassandra 就会调用压缩程序压缩 SSTable 文件,导致的结果就是重新建立 Key 的索引。这个过程可以用下图描述:
图 15 数据压缩

总结
本文首先描述了 Cassandra 中数据的主要的存储格式,包括内存中和磁盘中数据的格式,接下去介绍了 Cassandra 处理这些数据的方式,包括数据的添加、删除和修改,本质上修改和删除是一个操作。最后介绍了数据的压缩。
接下去两篇将向软件开发人员介绍 Cassandra 中使用的设计模式、巧妙的设计方法和 Cassandra 的高级使用方法——利用 Cassandra 搭建存储与检索一体化的实时检索系统
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































{kind=link}
{kind=link}
{kind=link}