
IP摄像头技术纵览(八)---进阶:VPN虚拟专网技术实现
【原创】IP摄像头技术纵览(八)—进阶:VPN虚拟专网技术实现
本文属于《IP摄像头技术纵览》系列文章之一:
Author: chad
Mail: [email protected]
本文可以自由转载,但转载请务必注明出处以及本声明信息。
上一节已经实现了UDP打洞,进而可以达到P2P通信的目的。使用UDP打洞基本已经能够完整解决IP摄像头的底层通信问题,但还不够完美。因为这只是在应用层实现了p2p,每个想利用P2P技术进行数据传输的程序都必须调用UDP打洞程序。有没有网络层实现P2P的方法呢?换句话说就是有没有用户联网游戏、文件共享、远程访问、视频会议等大量的互联网应用不需要修改就能使用UDP打洞技术进行P2P通信的方案呢?
答案就是VPN。
一、VPN技术简介
VPN的官方解释是这样的:
VPN的英文全称是“Virtual Private Network”,翻译过来就是“虚拟专用网络”。虚拟专用网络我们可以把它理解成是虚拟出来的企业内部专线。它可以通过特殊的加密的通讯协议在连接在Internet上的位于不同地方的两个或多个企业内部网之间建立一条专有的通讯线路。在企业网络中有广泛应用。VPN网关通过对数据包的加密和数据包目标地址的转换实现远程访问。VPN有多种分类方式,主要是按协议进行分类。VPN可通过服务器、硬件、软件等多种方式实现。VPN具有成本低,易于使用的特点。
VPN即虚拟专用网,是通过一个公用网络(通常是因特网)建立一个临时的、安全的连接,是一条穿过混乱的公用网络的安全、稳定的隧道。通常,VPN是对企业内部网的扩展,通过它可以帮助远程用户、公司分支机构、商业伙伴及供应商同公司的内部网建立可信的安全连接,并保证数据的安全传输。VPN可用于不断增长的移动用户的全球因特网接入,以实现安全连接;可用于实现企业网站之间安全通信的虚拟专用线路,用于经济有效地连接到商业伙伴和用户的安全外联网虚拟专用网。
上面的解释虽然很对,但是对于初次接触VPN(最多用vpn翻个墙)的初学者来说完全是扯淡,“企业”、“隧道”这些高大上的名词堆砌把人绕的云里雾里的。现在让我来告诉你什么是VPN:

就是这么简单:没VPN之前P2P通信你要自己调用socket接口做UDP打洞程序;有了VPN后,你直接将数据交给标准socket接口就行了。UDP打洞之类那一套都有VPN搞定了。
看完上面的图,我们再来看正儿八经的VPN原理图:

VPN也就是通过一个公用网络(通常是因特网)建立一个临时的、安全的连接,是一条穿过混乱的公用网络的安全、稳定的隧道。

1 、VPN分类
根据不同的划分标准,VPN可以按几个标准进行分类划分:
1.1、按VPN的协议分类:
VPN的隧道协议主要有三种,PPTP、L2TP和IPSec,其中PPTP和L2TP协议工作在OSI模型的第二层,又称为二层隧道协议;IPSec是第三层隧道协议。
1.2、按VPN的应用分类:
(1)Access VPN(远程接入VPN):客户端到网关,使用公网作为骨干网在设备之间传输VPN数据流量;
(2)Intranet VPN(内联网VPN):网关到网关,通过公司的网络架构连接来自同公司的资源;
(3)Extranet VPN(外联网VPN):与合作伙伴企业网构成Extranet,将一个公司与另一个公司的资源进行连接。
1.3、按所用的设备类型进行分类:
网络设备提供商针对不同客户的需求,开发出不同的VPN网络设备,主要为交换机、路由器和防火墙:
(1)路由器式VPN:路由器式VPN部署较容易,只要在路由器上添加VPN服务即可;
(2)交换机式VPN:主要应用于连接用户较少的VPN网络;
(3)防火墙式VPN:防火墙式VPN是最常见的一种VPN的实现方式,许多厂商都提供这种配置类型
1.4.按照实现原理划分:
(1)重叠VPN:此VPN需要用户自己建立端节点之间的VPN链路,主要包括:GRE、L2TP、IPSec等众多技术。
(2)对等VPN:由网络运营商在主干网上完成VPN通道的建立,主要包括MPLS、VPN技术。
2、VPN技术
2.1、隧道技术
实现VPN,最关键部分是在公网上建立虚信道,而建立虚信道是利用隧道技术实现的,IP隧道的建立可以是在链路层和网络层。第二层隧道主要是PPP连接,如PPTP,L2TP,其特点是协议简单,易于加密,适合远程拨号用户;第三层隧道是IPinIP,如IPSec,其可靠性及扩展性优于第二层隧道,但没有前者简单直接。
2.2、隧道协议
隧道是利用一种协议传输另一种协议的技术,即用隧道协议来实现VPN功能。为创建隧道,隧道的客户机和服务器必须使用同样的隧道协议。
1)PPTP(点到点隧道协议)是一种用于让远程用户拨号连接到本地的ISP,通过因特网安全远程访问公司资源的新型技术。它能将PPP(点到点协议)帧封装成IP数据包,以便能够在基于IP的互联网上进行传输。PPTP使用TCP(传输控制协议)连接的创建,维护,与终止隧道,并使用GRE(通用路由封装)将PPP帧封装成隧道数据。被封装后的PPP帧的有效载荷可以被加密或者压缩或者同时被加密与压缩。
2) L2TP协议:L2TP是PPTP与L2F(第二层转发)的一种综合,他是由思科公司所推出的一种技术。
3)IPSec协议:是一个标准的第三层安全协议,它是在隧道外面再封装,保证了在传输过程中的安全。IPSec的主要特征在于它可以对所有IP级的通信进行加密。
3、VPN软件
关于VPN软件我只知道大名鼎鼎的OpenVPN,然后就是相对比较小众的n2n。OpenVPN无疑是Linux下开源VPN的先锋,提供了良好的性能和友好的用户GUI。OpenVPN允许参与建立VPN的单点使用预设的私钥,第三方证书,或者用户名/密码来进行身份验证。它大量使用了OpenSSL加密库,以及SSLv3/TLSv1协议。OpenVPN能在Linux、xBSD、Mac OS X与Windows 2000/XP上运行。它并不是一个基于Web的VPN软件,也不与IPsec及其他VPN软件包兼容。
总之,OpenVPN非常强大,强大的另一层涵义就是功能复杂。相反,n2n却功能完善,结构简单,n2n_v1版本的代码文件总共10个。非常适合嵌入式开发,移植非常简单。并且,OpenVPN与n2n的的技术核心都是虚拟网卡,所以,研究完n2n就一道明白了OpenVPN的工作原理。
*关于翻墙:
《环球时报》英文版1月23日发文称,中国防火墙开始屏蔽外国VPN服务。VPN供应商Astrill上周通知用户,由于防火墙的升级,使用IPSec、L2TP/IPSec和PPTP协议的设备无法访问它的服务。另一家VPN服务商VPN Tech Runo本月早些时候称,从去年12月31日开始它的很多IP地址已被屏蔽,部分地区使用L2TP协议的用户也连接不了它的服务器。而免费VPN服务商fqrouter也在本月8日正式宣布关闭其VPN服务。路透社表示,StrongVPN和Goden Frog公司的相关服务也受到影响。StrongVPN在它的官方博客表示,它的某些伺服器无法为中国用户提供服务,Golden Frog则声称,它的VPN服务过去几天受到的干扰加剧。Golden Frog总裁Sunday Yokubaitis坦言:“我们和其他VPN服务供应商本周(这里指上周)受到的攻击是前所未有的,比以往都更加复杂。”*
二、TUN/TAP 虚拟网卡
虚拟网卡是使用网络底层编程技术实现的一个驱动软件,安装后在主机上多出现一个网卡,可以像其它网卡一样进行配置。服务程序可以在应用层打开虚拟网卡,如果应用软件(如IE)向虚拟网卡发送数据,则服务程序可以读取到该数据,如果服务程序写合适的数据到虚拟网卡,应用软件也可以接收得到。虚拟网卡在很多的操作系统下都有相应的实现。
虚拟网卡Tun/tap驱动是一个开源项目,支持很多的类UNIX平台,OpenVPN和Vtun都是基于它实现隧道包封装。
tun/tap驱动程序实现了虚拟网卡的功能,tun表示虚拟的是点对点设备,tap表示虚拟的是以太网设备,这两种设备针对网络包实施不同的封装。利用tun/tap驱动,可以将tcp/ip协议栈处理好的网络分包传给任何一个使用tun/tap驱动的进程,由进程重新处理后再发到物理链路中。
1、Tun/tap驱动程序工作原理简介
做为虚拟网卡驱动,Tun/tap驱动程序的数据接收和发送并不直接和真实网卡打交道,而是通过用户态来转交。在linux下,要实现核心态和用户态数据的交互,有多种方式:可以通用socket创建特殊套接字,利用套接字实现数据交互;通过proc文件系统创建文件来进行数据交互;还可以使用设备文件的方式,访问设备文件会调用设备驱动相应的例程,设备驱动本身就是核心态和用户态的一个接口,Tun/tap驱动就是利用设备文件实现用户态和核心态的数据交互。
从结构上来说,Tun/tap驱动并不单纯是实现网卡驱动,同时它还实现了字符设备驱动部分。以字符设备的方式连接用户态和核心态。下面是示意图:

Tun/tap驱动程序中包含两个部分,一部分是字符设备驱动,还有一部分是网卡驱动部分。利用网卡驱动部分接收来自TCP/IP协议栈的网络分包并发送或者反过来将接收到的网络分包传给协议栈处理,而字符驱动部分则将网络分包在内核与用户态之间传送,模拟物理链路的数据接收和发送。Tun/tap驱动很好的实现了两种驱动的结合。
值得注意的是:一次read系统调用,有且只有一个数据包被传送到用户空间,并且当用户空间的缓冲区比较小时,数据包将被截断,剩余部分将永久地消失,write系统调用与read类似,每次只发送一个数据包。所以在编写此类程序的时候,请用足够大的缓冲区 ,直接调用系统调用read/write ,避免采用C语言的带缓存的IO函数。
2、虚拟网卡的内核配置
可以直接将虚拟网卡驱动编译进内核,也可以将虚拟网卡部分编译成内核模块,然后手动加载到内核中。
2.1、配置内核
make menuconfig调出配置菜单,配置虚拟网卡设备[M]
Device Drivers => Network device support => Universal TUN/TAP device driver support [M]
2.2、编译内核模块
#make modulse
2.3、将编译好的模块下载到开发板,并加载模块
#insmod tun.ko
2.4、创建虚拟网卡设备
#mknod /dev/net/tun c 10 200补充:
2.4的核:TUN 设备号是36 16+,文件节点:/dev/tun0
2.6的核:TUN 设备号是10 200,文件节点:/dev/net/tunTAP:对应以太网设备
TUN:点对点设备
2.5、查看内核加载模块
#lsmod
veth 5280 0 - Live 0xbf029000
tun 12824 0 - Live 0xbf020000
3、虚拟网卡测试
执行到这一步时,配置虚拟网卡可以直接使用命令,例如下面的例子:

也可以使用程序进行控制,如下一个小实例:
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <sys/socket.h>
#include <sys/ioctl.h>
#include <linux/if.h>
#include <linux/if_tun.h>
#include <sys/types.h>
#include <errno.h>
#include <net/route.h>
#include <ctype.h>
#define IS_GRAPH(c) isgraph(c)?c:‘.‘
/**
* 激活接口
*/
int interface_up(char *interface_name)
{
int s;
if((s = socket(PF_INET,SOCK_STREAM,0)) < 0)
{
printf("Error create socket :%m\n");
return -1;
}
struct ifreq ifr;
strcpy(ifr.ifr_name,interface_name);
short flag;
flag = IFF_UP;
if(ioctl(s, SIOCGIFFLAGS, &ifr) < 0)
{
printf("Error up %s :%m\n",interface_name);
return -1;
}
ifr.ifr_ifru.ifru_flags |= flag;
if(ioctl(s, SIOCSIFFLAGS, &ifr) < 0)
{
printf("Error up %s :%m\n",interface_name);
return -1;
}
return 0;
}
/**
* 设置接口ip地址
*/
int set_ipaddr(char *interface_name, char *ip)
{
int s;
if((s = socket(PF_INET, SOCK_STREAM, 0)) < 0)
{
printf("Error up %s :%m\n",interface_name);
return -1;
}
struct ifreq ifr;
strcpy(ifr.ifr_name, interface_name);
struct sockaddr_in addr;
bzero(&addr, sizeof(struct sockaddr_in));
addr.sin_family = PF_INET;
inet_aton(ip, &addr.sin_addr);
memcpy(&ifr.ifr_ifru.ifru_addr, &addr, sizeof(struct sockaddr_in));
if(ioctl(s, SIOCSIFADDR, &ifr) < 0)
{
printf("Error set %s ip :%m\n",interface_name);
return -1;
}
return 0;
}
/**
* 创建接口
*/
int tun_create(char *dev, int flags)
{
struct ifreq ifr;
int fd, err;
if ((fd = open("/dev/net/tun", O_RDWR)) < 0)
{
printf("Error :%m\n");
return -1;
}
memset(&ifr, 0, sizeof(ifr));
ifr.ifr_flags |= flags;
if (*dev != ‘\0‘)
{
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
if ((err = ioctl(fd, TUNSETIFF, (void *)&ifr)) < 0)
{
printf("Error :%m\n");
close(fd);
return -1;
}
strcpy(dev, ifr.ifr_name);
return fd;
}
/**
* 增加到10.0.0.1的路由
* 同命令:route add 10.0.0.1 dev tun0
*/
int route_add(char * interface_name)
{
int skfd;
struct rtentry rt;
struct sockaddr_in dst;
struct sockaddr_in gw;
struct sockaddr_in genmask;
memset(&rt, 0, sizeof(rt));
genmask.sin_addr.s_addr = inet_addr("255.255.255.255");
bzero(&dst,sizeof(struct sockaddr_in));
dst.sin_family = PF_INET;
dst.sin_addr.s_addr = inet_addr("10.0.0.1");
rt.rt_metric = 0;
rt.rt_dst = *(struct sockaddr*) &dst;
rt.rt_genmask = *(struct sockaddr*) &genmask;
rt.rt_dev = interface_name;
rt.rt_flags = RTF_UP | RTF_HOST ;
skfd = socket(AF_INET, SOCK_DGRAM, 0);
if(ioctl(skfd, SIOCADDRT, &rt) < 0)
{
printf("Error route add :%m\n");
return -1;
}
}
int main(int argc, char *argv[])
{
int tun, ret;
char tun_name[IFNAMSIZ];
unsigned char buf[4096];
unsigned char ip[4];
tun_name[0] = ‘\0‘;
tun = tun_create(tun_name, IFF_TUN | IFF_NO_PI);
if (tun < 0)
{
return 1;
}
printf("TUN name is %s\n", tun_name);
//激活虚拟网卡增加到虚拟网卡的路由
interface_up(tun_name);
route_add(tun_name);
while (1) {
ret = read(tun, buf, sizeof(buf));
printf("read %d bytes\n", ret);
int i;
for(i=0;i<ret;i++)
{
printf("%02x ",buf[i]);
}
printf("\n");
for(i=0;i<ret;i++)
printf("%c",IS_GRAPH(buf[i]));
printf("\n");
if (ret < 0)
break;
memcpy(ip, &buf[12], 4);
memcpy(&buf[12], &buf[16], 4);
memcpy(&buf[16], ip, 4);
buf[20] = 0;
*((unsigned short*)&buf[22]) += 8;
ret = write(tun, buf, ret);
printf("write %d bytes\n", ret);
}
return 0;
}以上代码简答地处理了ICMP的ECHO包,并回应以ECHO REPLY。
首先运行这个程序:

接着在另外一个终端运行如下命令:
ping 10.0.0.1
然后可以看到,打印出的数据如下:

对照L3层帧格式–IP帧格式如下:

这就是tun 点对点通信的原意:IP层通信。如果将程序中:
tun = tun_create(tun_name, IFF_TUN | IFF_NO_PI);
修改为:
tun = tun_create(tun_name, IFF_TAP | IFF_NO_PI);
则打印出的会是以太网协议帧即L2层协议,n2n使用的既是L2层协议。大家可以自己测试。
三、n2n—内网穿透神器
1、n2n介绍
2008年,ntop的作者Luca Deri开始研究p2p VPN,他一方面看到公众对p2p VPN有着强烈的需求,另一方面又不满足已有产品的现状,于是n2n诞生了。n2n是一个完全开源的软件,软件由两部分组成:supernode和edge。supernode就是中心节点(服务端),既然是p2p,开始建立的时候需要一个中间节点来找到对方。
n2n是一个二层点对点虚拟专用网(VPN),它允许用户在网络层面而非应用层面开发典型的P2P应用功能。这就意味着,用户可以获得本地IP可见性(如,属于同一个n2n网络的两台PC可以互相ping通),以及不管他们现在身处哪个网络,只要有相同的网络IP地址就可以访问到。简言之,就像OpenVPN将SSL从应用(如,用于部署https协议)搬到了网络协议一样,n2n将P2P从应用搬到了网络层面。
n2n是一个基于P2P协议的加密的二层专用网。加密使用开放协议部署在边缘节点,它使用用户定义的加密钥匙,由你自己控制安。各个n2n用户可以同时属于多个网络(或者社区)。它拥有在反向通信方向(如,从外部到内部)穿越NAT和防火墙的能力,因此可以到达n2n节点,即使运行在一个专用网中。防火墙不再是IP层面掌控通信的障碍。n2n网络并不意味着它是独立的,它可以在n2n和非n2n网络间路由通信。
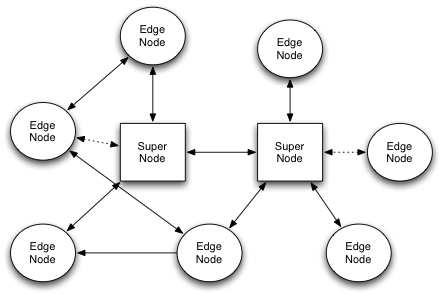
如上图所示,n2n架构基于两个组件:
超级节点:它在启动时用于边缘节点或用于达到对称防火墙后面的节点。对于这些节点,该应用主要是一个目录暂存器和包路由器,而不是直接通信。
边缘节点:安装在用户PC的应用程序,它允许构建n2n网络。实际上,各个边缘节点创建一个tun/tap设备,该设备是n2n网络的进入点。
2、安装n2n到Ubuntu
打开终端并运行以下命令:
$ sudo apt-get install subversion build-essential libssl-dev
$ svn co https://svn.ntop.org/svn/ntop/trunk/n2n
$ cd n2n/n2n_v2
$ make
$ sudo make install
3、使用n2n
首先,我们需要配置一个超级节点和任意数量的边缘节点。
假设你将它放到了主机a.b.c.d的portx端口上。使用密码encryptme。同时,为我们的网络起个名字:mynetwork。为了不与本地局域网的ip冲突,我们使用A类私有网络段:10.1.2.0/24。
(1)配置超级节点
#./supernode -l portx#监听指定端口

(2)配置边缘节点
在各个边缘节点,使用以下命令:
节点1上:
#./edge -a 10.1.2.1-c mynetwork -k encryptme -l a.b.c.d:portx
节点2上:
#./edge -a 10.1.2.2-c mynetwork -k encryptme -l a.b.c.d:portx
我们可以查看网络设备情况如下:

接下来我们就可以测试了,各种网络测试,如:

或者切入我们的正体,IP摄像头测试:

四、n2n实现分析
在n2n目录下的各文件大致功能说明如下:
- edge.c:客户端实现
- supernode.c:服务器端实现
- minilzo.c:数据压缩处理
- n2n.c:通用函数实现
- tuntap_linux.c:linux tun/tap设备接口实现
- twofish.c:twofish加密算法的实现
分析N2N源码抓住以下三点即可:
- 数据结构。
- 帧结构。
- 程序流程
1、数据结构
主要的数据结构如下:
/* Set N2N_COMPRESSION_ENABLED to 0 to disable lzo1x compression of ethernet
* frames. Doing this will break compatibility with the standard n2n packet
* format so do it only for experimentation. All edges must be built with the
* same value if they are to understand each other. */
#define N2N_COMPRESSION_ENABLED 1
#define DEFAULT_MTU 1400
/* Maximum enum value is 255 due to marshalling into 1 byte */
enum packet_type {
packet_unreliable_data = 0, /* no ACK needed */
packet_reliable_data, /* needs ACK */
packet_ping,
packet_pong
};
/* All information is always in network byte-order */
struct peer_addr {
u_int8_t family;
u_int16_t port;
union {
u_int8_t v6_addr[16];
u_int32_t v4_addr;
} addr_type;
};
struct n2n_packet_header {
u_int8_t version, msg_type, ttl, sent_by_supernode;
char community_name[COMMUNITY_LEN], src_mac[6], dst_mac[6];
struct peer_addr public_ip, private_ip;
enum packet_type pkt_type;
u_int32_t sequence_id;
u_int32_t crc; // FIX - It needs to be handled for detcting forged packets
};
int marshall_n2n_packet_header( u_int8_t * buf, const struct n2n_packet_header * hdr );
int unmarshall_n2n_packet_header( struct n2n_packet_header * hdr, const u_int8_t * buf );
#define N2N_PKT_HDR_SIZE (sizeof(struct n2n_packet_header))
// 由于存在字节对齐等影响,所以N2N_PKT_HDR_SIZE 只能用于内存申请分配时使用,不能作为数据封包时使用。
/** Common type used to hold stringified IP addresses. */
typedef char ipstr_t[32];
/** Common type used to hold stringified MAC addresses. */
typedef char macstr_t[32];
struct n2n_sock_info
{
int sock;
char is_udp_socket /*= 1*/;
};
typedef struct n2n_sock_info n2n_sock_info_t;
struct peer_info {
char community_name[COMMUNITY_LEN], mac_addr[6];
struct peer_addr public_ip, private_ip;
time_t last_seen;
struct peer_info *next;
/* socket */
n2n_sock_info_t sinfo;
};
struct n2n_edge; /* defined in edge.c */
typedef struct n2n_edge n2n_edge_t;2、Supernode程序分析
(1)程序流程图


(2)主要函数
//数据转发函数
static size_t forward_packet(char *packet, u_int packet_len,
struct peer_addr *sender,
n2n_sock_info_t * sinfo,
struct n2n_packet_header *hdr )
{
//增加TTL值
hdr->ttl++; /* FIX discard packets with a high TTL */
//判断目标地址是否是广播地址
is_dst_broad_multi_cast = is_multi_broadcast(hdr->dst_mac);
//发送者的公网IP信息
memcpy(&hdr->public_ip, sender, sizeof(struct peer_addr));
//标识该帧数据是由supernode 封装的
hdr->sent_by_supernode = 1;
//将hdr中的信息转换成字节码packet
marshall_n2n_packet_header( (u_int8_t *)packet, hdr );
if ( is_dst_broad_multi_cast ) //如果是广播数据则进行广播发送
{
numsent = broadcast_packet( packet, packet_len, sender, sinfo, hdr );
}
Else //否则发送到指定目标
{
//从注册链表中找出目标mac对应的IP信息,L2层协议,所以通过mac路由
scan = find_peer_by_mac( known_peers, hdr->dst_mac );
if ( scan )
{
//将数据发送到目标节点
send_data( &(scan->sinfo), packet, &len, &scan->public_ip, 0);
}
else
{
//广播发送
broadcast_packet( packet, packet_len, sender, sinfo, hdr );
}
}
return numsent;
}关键函数分析:
//数据接收函数
receive_data(
n2n_sock_info_t * sinfo, //socket_fd
char *packet, //recbuf
size_t packet_len, //buf size
struct peer_addr *from, //通过recvfrom 获取发送者公网ip信息
u_int8_t *discarded_pkt, //实际未使用
char *tun_mac_addr, //实际未使用
u_int8_t decompress_data, //=1 则解密数据 ,supernode中设置为0
struct n2n_packet_header *hdr //将解析出的帧头数据填入该结构体
)
//数据处理函数
void handle_packet( char *packet, //接收到的数据帧
u_int packet_len, //帧长
struct peer_addr *sender, //发送者IP信息
n2n_sock_info_t * sinfo //socket_fd
)
//数据转发函数
forward_packet( char *packet, //接收到的数据帧
u_int packet_len, //接收到的数据帧长度
struct peer_addr *sender, //数据发送者IP信息
n2n_sock_info_t * sinfo, //socket_fd
struct n2n_packet_header *hdr //结构化帧头信息
)3、Edge节点程序分析
(1)主要结构体
struct n2n_edge
{
u_char re_resolve_supernode_ip;
struct peer_addr supernode;
char supernode_ip[48];
char * community_name /*= NULL*/;
/* int sock; */
/* char is_udp_socket /\*= 1*\/; */
n2n_sock_info_t sinfo;
u_int pkt_sent /*= 0*/;
tuntap_dev device;
int allow_routing /*= 0*/;
int drop_ipv6_ndp /*= 0*/;
char * encrypt_key /* = NULL*/;
TWOFISH * enc_tf;
TWOFISH * dec_tf;
struct peer_info * known_peers /* = NULL*/;
struct peer_info * pending_peers /* = NULL*/;
time_t last_register /* = 0*/;
};(2)程序流程图


**********eth帧结构***********
struct ethhdr {
unsigned char h_dest[ETH_ALEN];
unsigned char h_source[ETH_ALEN];
__be16 h_proto;
} __attribute__((packed));
struct ether_header
{
u_int8_t ether_dhost[ETH_ALEN]; // destination eth addr
u_int8_t ether_shost[ETH_ALEN]; // source ether addr
u_int16_t ether_type; // packet type ID field
} __attribute__ ((__packed__));
4、程序之外隐藏的技术
如果不了解tcp/ip协议栈,分析n2n程序会依然非常迷惑:n2n是如何实现udp打洞的?
其实,在n2n源码中对应n2n的工作流程已经写的很清楚了,我迷惑很久最后才发现原来在文件HACKING中已经说明。
下面的英文还是蛮简单的,我也懒得翻译了,大家自己看看就明白n2n工作原理了。
REGISTRATION AND PEER-TO-PEER COMMUNICATION SETUP
-------------------------------------------------
A and B are edge nodes with public sockets Apub and Bpub; and private network
addresses A and B respectively. S is the supernode.
A sends {REGISTER,Amac} to S. S registers {Amac->Apub}.
B sends {REGISTER,Bmac} to S. S registers {Bmac->Bpub}.
Now ping from A to B.
A sends broadcast "arp who-has B" to S. S relays the packet to all known edge
nodes. B replies "B at Bmac" to supernode which forwards this to A. So now ping
A->B is known to be ping Amac(A)->Bmac(B). Note: gratuitous arp also requires
discussion.
In response to receiving the arp reply, Apub sends {REGISTER,Amac} to Bpub. If
Bpub receives the request it sends back {REGISTER_ACK,Amac} and also sends its
own {REGISTER,Bmac} request.
In response to receiving the "arp who-has", Bpub sends {REGISTER,Bmac} to Apub.
Now the OS has received the arp reply and sends ICMP to Bmac(B) via the tunnel
on A. A looks up Bmac in the peers list and encapsulates the packet to Bpub or
the supernode if the MAC is not found.
We assume that between two edge nodes, if Bpub receives a packet from Apub then
Apub can receive a packet from Bpub. This is the symmetric NAT case. Note: In
the symmetric NAT case, the public socket for a MAC address will be different
for direct contact when compared to information from the supernode.
When two edge nodes are both behind symmetric NAT they cannot establish direct
communication.
If A receives {REGISTER,Bmac} from B, A adds {Bmac->Bpub} to its peers list
knowing that Bmac is now reachable via that public socket. Similarly if B
receives {REGISTER,Amac} from A.
The supernode never forwards REGISTER messages because the public socket seen by
the supervisor for some edge (eg. A) may be different to the socket seen by
another edge due to the actions of symmetric NAT (alocating a new public socket
for the new outbound UDP "connection").
EDGE REGISTRATION DESIGN AMMENDMENTS (starting from 2008-04-10)
------------------------------------
* Send REGISTER on rx of PACKET or REGISTER only when dest_mac == device MAC
(do not send REGISTER on Rx of broadcast packets).
* After sending REGISTER add the new peer to pending_peers list; but
* Don‘t send REGISTER to a peer in pending_peers list
* Remove old entries from pending_peers at regular intervals
* On rx of REGISTER_ACK, move peer from pending_peers to known_peers for direct
comms and set last_seen=now
* On rx of any packet set last_seen=now in the known_peers entry (if it
exists); but do not add a new entry.
* If the public socket address for a known_peers entry changes, deleted it and
restart registration to the new peer.
* Peer sockets provided by the supernode are ignored unless no other entry
exists. Direct peer-to-peer sockets are always given more priority as the
supernode socket will not be usable for direct contact if the peer is behind
symmetric NAT.
The pending_peers list concept is to prevent massive registration traffic when
supernode relay is in force - this would occur if REGISTER was sent for every
incident packet sent via supernode. Periodic REGISTER attempts will still occur;
not for every received packet. In the case where the peer cannot be contacted
(eg. both peers behind symmetric NAT), then there will still be periodic
attempts. Suggest a pending timeout of about 60 sec.
A peer is only considered operational for peer-to-peer sending when a
REGISTER_ACK is returned. Once operational the peer is kept operational while
any direct packet communications are occurring. REGISTER is not required to
keep the path open through any firewalls; just some activity in one direction.
After an idle period; the peer should be deleted from the known_peers list. We
should not try to re-register when this time expires. If there is no data to
send then forget the peer. This helps scalability.
If a peer wants to be remembered it can send gratuitous ARP traffic which will
keep its entry in the known_peers list of any peers which already have the
entry.
peer = find_by_src_mac( hdr, known_peers ); /* return NULL or entry */
if ( peer )
{
peer_last_seen = time(NULL);
}
else
{
if ( ! is_broadcast( hdr ) ) /* ignore broadcasts */
{
if ( IS_REGISTER_ACK( hdr ) )
{
/* move from pending to known_peers */
set_peer_operational( hdr );
}
else
{
/* add to pending and send REGISTER - ignore if in pending. */
try_send_register( hdr )
}
}
}
(Notes):
* In testing it was noted that if a symmetric NAT firewall shuts down the UDP
association but the known_peers registration is still active, then the peer
becomes unreachable until the known_peers registration is deleted. Suggest two
ways to mitigate this problem:
(a) make the known_peers purge timeout a config paramter;
(b) send packets direct and via supernode if the registration is older than
eg. 60 sec.
GRATUITOUS ARP
--------------
In addition to the ARP who-has mechanism noted above, two edge nodes can become
aware of one another by gratuitous ARP. A gratuitous ARP packet is a broadcast
packet sent by a node for no other purpose than to announce its presence and
identify its MAC and IP address. Gratuitous ARP packets are to keep ARP caches
up to date so contacting the host will be faster after an long idle time.
MAN PAGES
---------
Look at a non-installed man page like this (linux/UNIX):
nroff -man edge.8 | less
PACKET FORMAT
-------------
Version 1
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
0 ! Version=1 ! Message Type ! TTL ! Origin !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
4 ! !
8 ! Community Name !
12 ! !
16 ! !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
20 ! Source MAC Address :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
24 : Source MAC Address ! Destination MAC Address :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
28 : Destination MAC Address !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
32 ! Public Peer !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
40 : :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
48 : ! Alignment !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
! Private Peer :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
56 : :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
64 : :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: ! Alignment !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
72 ! Packet Type !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
! Seq Number !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
80 ! CRC32 !
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Payload
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Version = 1
MessageType = 1
TTL = 1
Origin = 1
Community = 16
src MAC = 6
dst MAC = 6
Pub Peer = 19 (20)
Priv Peer = 19 (20)
Pkt Type = 1 (4)
Seq = 4
CRC = 4
======================
Total = 79 (84)
Sizes in parentheses indicate alignment adjusted sizes on i686. The intel
alignment is also shown in the diagram. Some platforms have different alignment
padding.
The above packet format describes the header of IP packets carried between edge
nodes. Payload is an encoded ethernet frame appended to the packet header. The
ethernet payload is encrypted and compressed.
When the payload is created it is first encrypted with twofish, then compressed
using lzo1x_compress. When the payload is decoded it is first decompressed using
lzo1x_decompress_safe then decrypted using twofish.郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。

































