
在Linux如何让更改文件的字符编码
问题:在我的 Linux 系统中有一个编码为 iso-8859-1 的字幕文件,其中部分字符无法正常显示,我想把文本改为 utf8 编码。在 Linux 中, 有没有一个好的工具来转换文本文件的字符编码?
正如我们所知道的那样,电脑只能够处理低级的二进制值,并不能直接处理字符。当一个文本文件被存储时,文件中的每一个字符都被映射成二进制值,实际存储在硬盘中的正是这些“二进制值”。之后当程序打开文本文件时,所有二进制值都被读入并映射回原始的可读字符。只有当所有需要访问这个文件的程序都能够“理解”它的编码,即二进制值到字符的映射时,这个“保存和打开”的过程才能很好地完成,这也确保了可理解数据的往返过程。
如果不同的程序使用不同的编码来处理同一个文件,源文件中的特殊字符就无法正常显示。这里的特殊字符指的是非英文字母的字符,例如带重音的字符(比如 ñ,á,ü)。
然后问题就来了: 1)我们如何确定一个确定的文本文件使用的是什么字符编码? 2)我们如何把文件转换成已选择的字符编码?
步骤一
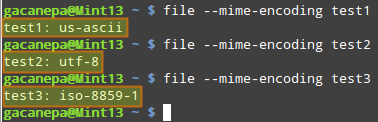
为了确定文件的字符编码,我们使用一个名为 “file” 的命令行工具。因为 file 命令是一个标准的 UNIX 程序,所以我们可以在所有现代的 Linux 发行版中找到它。
运行下面的命令:
$ file --mime-encoding filename
步骤二
下一步是查看你的 Linux 系统所支持的文件编码种类。为此,我们使用名为 iconv 的工具及 “-l” 选项(L 的小写)来列出所有当前支持的编码。
$ iconv -l
iconv 工具是 GNU libc 库组成部分,因此它在所有 Linux 发行版中都是开箱即用的。
步骤三
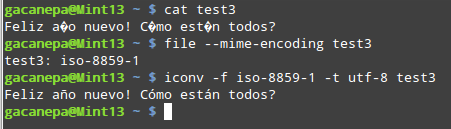
在我们在我们的 Linux 系统所支持的编码里面选定了目标编码之后,运行下面的命令来完成编码转换:
$ iconv -f old_encoding -t new_encoding filename
例如,把 iso-8859-1 编码转换为 utf-8 编码:
$ iconv -f iso-8859-1 -t utf-8 input.txt
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































