
使用Eclipse运行Hadoop 2.x MapReduce程序常见问题
1、 当我们编写好MapReduce程序,点击Run on Hadoop的时候,Eclipse控制台输出如下内容:

这个信息告诉我们没有找到log4j.properties文件。如果没有这个文件,程序运行出错的时候,就没有打印日志,因此我们会很难调试。
解决方法:复制$HADOOP_HOME/etc/hadoop/目录下的log4j.properties文件到MapReduce项目 src文件夹下。
2、当执行MapReduce程序的时候,Eclipse可能会报告堆益处的错误。 此时,MapReduce程序执行的out目录已经被创建,但是此时目录为空,再重新运行程序之前我们需要删除这个输出目录。如下图所示:
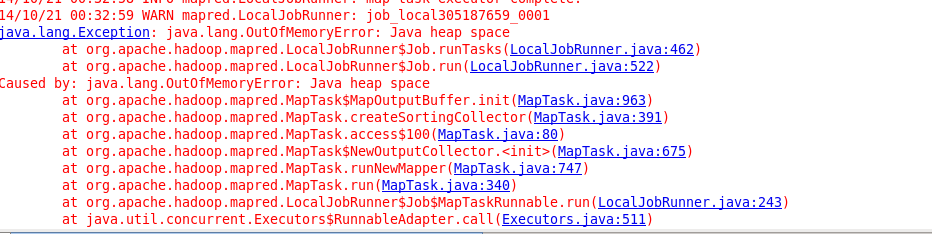

分析:首先我们可以输入命令(java -client -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal -version | grep -i heapsize),来查看当前JDK支持的最大堆。然后在此基础上增加堆大小。
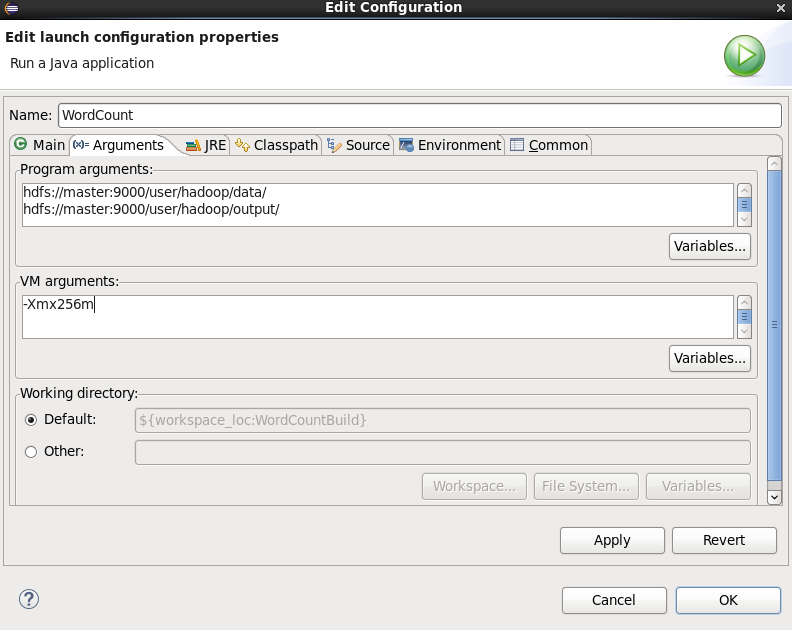
解决方案:在当前运行程序的运行配置中设置VM arguments参数,如下图所示:
3.Hadoop的本地库(Native Libraries)介绍
Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通过本地库,Hadoop可以更加高效地执行某一些操作。
目前在Hadoop中,本地库应用在文件的压缩上面:
在使用这两种压缩方式的时候,Hadoop默认会从$HADOOP_HOME/lib/native/Linux-*目录中加载本地库。
如果加载成功,输出为:
DEBUG util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
INFO util.NativeCodeLoader - Loaded the native-hadoop library
如果加载失败,输出为:
INFO util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
在Hadoop的配置文件core-site.xml中可以设置是否使用本地库:
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
Hadoop默认的配置为启用本地库。
另外,可以在环境变量中设置使用本地库的位置:
export JAVA_LIBRARY_PATH=/path/to/hadoop-native-libs
有的时候也会发现Hadoop自带的本地库无法使用,这种情况下就需要自己去编译本地库了。在$HADOOP_HOME目录下,使用如下命令即可:
ant compile-native
编译完成后,可以在$HADOOP_HOME/build/native目录下找到相应的文件,然后指定文件的路径或者移动编译好的文件到默认目录下即可。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































