
PageRank算法并行实现(二)
浏览数:41 /
时间:2015年06月08日
4). PageRank计算: PageRank.java
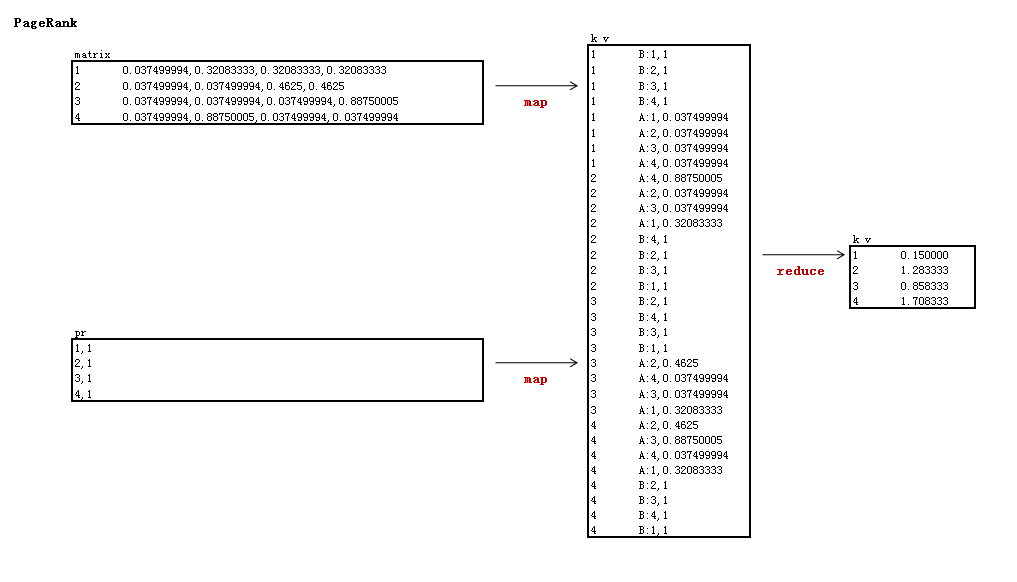
矩阵解释:
实现邻接与PR矩阵的乘法
map以邻接矩阵的行号为key,由于上一步是输出的是列,所以这里需要转成行
reduce计算得到未标准化的特征值
新建文件: PageRank.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class PageRank {
public static class PageRankMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// tmp1 or result
private static int nums = 4;// 页面数
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
String[] tokens = PageRankJob.DELIMITER.split(values.toString());
if (flag.equals("tmp1")) {
String row = values.toString().substring(0,1);
String[] vals = PageRankJob.DELIMITER.split(values.toString().substring(2));// 矩阵转置
for (int i = 0; i < vals.length; i++) {
Text k = new Text(String.valueOf(i + 1));
Text v = new Text(String.valueOf("A:" + (row) + "," + vals[i]));
context.write(k, v);
}
} else if (flag.equals("pr")) {
for (int i = 1; i <= nums; i++) {
Text k = new Text(String.valueOf(i));
Text v = new Text("B:" + tokens[0] + "," + tokens[1]);
context.write(k, v);
}
}
}
}
public static class PageRankReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
Map<Integer, Float> mapA = new HashMap<Integer, Float>();
Map<Integer, Float> mapB = new HashMap<Integer, Float>();
float pr = 0f;
for (Text line : values) {
System.out.println(line);
String vals = line.toString();
if (vals.startsWith("A:")) {
String[] tokenA = PageRankJob.DELIMITER.split(vals.substring(2));
mapA.put(Integer.parseInt(tokenA[0]), Float.parseFloat(tokenA[1]));
}
if (vals.startsWith("B:")) {
String[] tokenB = PageRankJob.DELIMITER.split(vals.substring(2));
mapB.put(Integer.parseInt(tokenB[0]), Float.parseFloat(tokenB[1]));
}
}
Iterator iterA = mapA.keySet().iterator();
while(iterA.hasNext()){
int idx = iterA.next();
float A = mapA.get(idx);
float B = mapB.get(idx);
pr += A * B;
}
context.write(key, new Text(PageRankJob.scaleFloat(pr)));
// System.out.println(key + ":" + PageRankJob.scaleFloat(pr));
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("tmp1");
String output = path.get("tmp2");
String pr = path.get("input_pr");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(PageRank.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input), new Path(pr));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
hdfs.rmr(pr);
hdfs.rename(output, pr);
}
}
5). PR标准化: Normal.java

矩阵解释:
对PR的计算结果标准化,让所以PR值落在(0,1)区间
新建文件:Normal.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Normal {
public static class NormalMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text("1");
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
context.write(k, values);
}
}
public static class NormalReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
List vList = new ArrayList();
float sum = 0f;
for (Text line : values) {
vList.add(line.toString());
String[] vals = PageRankJob.DELIMITER.split(line.toString());
float f = Float.parseFloat(vals[1]);
sum += f;
}
for (String line : vList) {
String[] vals = PageRankJob.DELIMITER.split(line.toString());
Text k = new Text(vals[0]);
float f = Float.parseFloat(vals[1]);
Text v = new Text(PageRankJob.scaleFloat((float) (f / sum)));
context.write(k, v);
System.out.println(k + ":" + v);
}
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("input_pr");
String output = path.get("result");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(Normal.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(NormalMapper.class);
job.setReducerClass(NormalReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
6). 启动程序: PageRankJob.java
新建文件:PageRankJob.java
package org.conan.myhadoop.pagerank;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class PageRankJob {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
Map<String, String> path = new HashMap<String, String>();
path.put("page", "logfile/pagerank/page.csv");// 本地的数据文件
path.put("pr", "logfile/pagerank/pr.csv");// 本地的数据文件
path.put("input", HDFS + "/user/hdfs/pagerank");// HDFS的目录
path.put("input_pr", HDFS + "/user/hdfs/pagerank/pr");// pr存储目
path.put("tmp1", HDFS + "/user/hdfs/pagerank/tmp1");// 临时目录,存放邻接矩阵
path.put("tmp2", HDFS + "/user/hdfs/pagerank/tmp2");// 临时目录,计算到得PR,覆盖input_pr
path.put("result", HDFS + "/user/hdfs/pagerank/result");// 计算结果的PR
try {
AdjacencyMatrix.run(path);
int iter = 3;
for (int i = 0; i < iter; i++) {// 迭代执行
PageRank.run(path);
}
Normal.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
public static JobConf config() {// Hadoop集群的远程配置信息
JobConf conf = new JobConf(PageRankJob.class);
conf.setJobName("PageRank");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
public static String scaleFloat(float f) {// 保留6位小数
DecimalFormat df = new DecimalFormat("##0.000000");
return df.format(f);
}
}郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































