
如何在发型不乱的前提下应对单日十亿计Web请求
原文地址:http://developer.51cto.com/art/201502/464640.htm
就在不久之前,AppLovin移动广告平台的单一广告请求数量突破了200亿大关——相当于每一秒钟处理50万项事务——其如火如荼的发展态势帮助众多品牌在激励现有客户的同时、从市场中拉拢到了新的买家。那么AppLovin是如何打造出这样一套有能力应对数百亿请求、但又无需对硬件及运维人员进行显著扩张的基础设施的呢?
在今天的文章中,我们将共同了解该公司如何发现并选择采用各类最佳实践,从而通过技术堆栈进化实现业务规模拓展。
极具成本效率的扩展思路
让我们首先从规模谈起。对于我们这些在AppLovin工作的家伙来说,极具成本效率的规模扩展方案意味着能够在大幅提升负载处理能力的同时、避免硬件或者人员的线性增长。如果我们只能通过采购双倍的服务器设备或者将人员数量提高一倍来实现请求处理能力倍增,那么这样的方案根本没什么实际意义。由于我们在构建基础设施时充分考虑到效率拓展需求,因此才能够在过去一年中将服务器的请求处理数量增加到此前的二十倍。
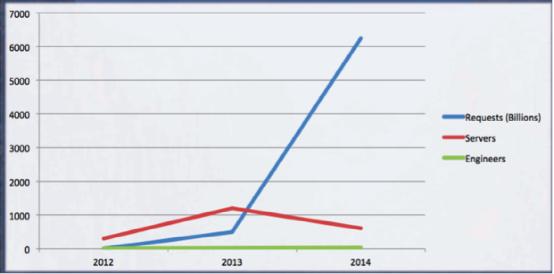
另一项值得注意的重点在于,对于大规模分布式系统而言,市面上并没有现成的解决方案可供借鉴。这类系统的构建工作必须使用自定义组件。无论归属于哪个行业,技术团队在建立分布式系统时都需要对选定的组件进行认真评估。除此之外,每一次出现工作负载爆炸式增长的时候,这些组件也需要及时作出调整。
针对这些调整制定规划意味着基础设施自身必须拥有出色的灵活性。我们从业务建立之初就充分意识到,移动广告领域可以说瞬息万变,而我们则需要打造一套能够与之相匹配且相适应的灵活基础设施。我们希望自己的这套基础设施能够允许员工针对各类市场需求实现对应的创新活动。举例来说,如果我们需要进行细节调整,那么只需在现有基础设施之上直接实施即可、而无需对设施整体进行重新设计。这就是我们工作的核心指导思想。
这套方案也切实带来了回报。我们最近刚刚将单月信息流量提升了一倍,而让这一切变成现实的正是我们这套灵活性出众的基础设施。
适应性强且具备可扩展能力的实时基础设施
考虑到上述构建要求,我们所打造的基础设施堆栈中包含Web服务器、一套实时缓存层、数据库、分布式消息服务以及大规模并行计算系统。
作为前端的是成百上千台Web服务器。这些服务器设备用于应答每天来自海量用户的数十亿请求。当每一条请求传入时,我们需要立刻作出一系列决定,包括是否对其作出应答、为其支付多少成本以及提供哪条广告作为宣传内容——整个决定过程大约耗时50毫秒。
接下来我们要做的是将用户配置信息纳入缓存,整套数据库包含数十亿拥有手机设备的用户。这些信息需要在很段的时间周期内进入可用状态,从而实现Web服务器的响应并决定是否为特定广告请求提供支持。简而言之,我们需要的是一套分布式缓存层,旨在以实时方式为全部传入请求提供所需数据。这套缓存层中使用包括Aerospike、Redis以及Memchached在内的多套系统。
除此之外,另有大量分析、报告、数据仓库以及数据科学功能集需要接入到不同类型的数据库当中。从宏观规模角度看,这些功能必须具备分布式能力。为了实现这种分布式机制,我们采用分布式消息或者发布/订阅消息服务。分布式消息发送机制为我们带来了以下几项关键优势:
·我们能够从任何位置获取需要的信息。
·我们能够利用日志文件作为事务单元,从而处理在一秒钟内处理数以十万计请求。
·我们能够为任何服务订阅方案提供其需要的信息。
上述消息必须被发布到全球世界内的任何位置。其目标位置可能是一套惠普Vertica数据仓库、MySQL数据库、Apache Hadoop系统或者一套Apache Storm实时处理系统。分布式消息发送机制可以说是所有实时架构的核心组成部分。
最后,我们需要利用分布式计算体系实现数据处理。拥有分布式计算体系意味着对Hadoop或者Apache Spark等技术方案的运用——这类并行处理系统能够查看全部数据并通过扩展处理规模庞大的数据负载。
以上列出的所有部件都通过一套分布式日志架构实现对接。这类基于日志架构的基本设计思路在于,它能够接纳多种数据源,利用日志文件作为事务单元并获取来自全部数据源的信息。举例来说,一台广告服务器可能会记录下“我是否提供了广告内容?用户是否点击过广告内容?我是否感知到事务处理?”这一切都将被写入日志当中,而大量日志信息则汇聚成消息系统。这些日志不断传输、接受处理,最后的汇总数据则被写入数据库。全部此类数据都能够为日志记录系统所调用,并以订阅方式交付给任何需要这些数据的服务。
这种架构类型之所以能够实现创新,是因为我们完全可以将任何组件插入到系统当中。大家可能需要在特定位置插入Aerospike实时数据库,也可能希望在其它位置使用Vertica。我们必须有能力将全部输入信息交付给全部不同类型的处理工具。拥有这样一套基于日志的架构能够帮助我们通过日志将所有数据源同集中式日志记录系统对接起来,并最终成为实时订阅系统的实现基础。
评估技术选项
对我们这套平台的评估工作能够充分展示,为什么拥有具备高度灵活性的基础设施是如此重要。
我们最初其实选择了利用PHP语言进行平台构建。这是一种效率极高的开发方式,而且也很容易找到大量熟悉此类开发任务的编程人员。同样的道理也适用于MySQL,而考虑到MongoDB作为NoSQL数据库领域重要成员的崇高地位,我们决定将二者并行使用。当然,作为一家初创企业,我们在起步阶段在Amazon Web Services上构建起平台的核心主体。但最后,我们利用RabbitMQ来实现自己的发布/订阅消息机制。
随着时间的推移,我们已经开始将数据迁移到由Aerospike、Redis、Apache Cassandra、Vertica以及Hadoop系统所共同构成的综合体系当中。我们完成了由PHP向C++的转换,而且将消息发布任务由RabbiMQ转换到一套定制化Java系统当中。与此同时,我们还成功削减了其它系统的使用数量,将其规模严格控制在我们相对易于理解、而工程技术团队又明白该如何处理的程度上。
新软件的引进无疑是个成本昂贵的命题。无论是开源软件还是专有许可软件,如果大家作出了尝试但却没能收到预期中的效果,那么整个工作就又得退回几个月之前。因此我们认真对每款产品进行了评估,希望能预先了解其是否物有所值。
我们采取的第一项举措是审视行业中的其它厂商在使用哪些产品,这些产品又能给我们的现有用例带来哪些改进。举例来说,当评估Aerospike时,来自另一家广告技术企业的工作人员就向我们介绍了他的经验。我们之后又与四、五家其它Aerospike客户进行了沟通,并提出“你们的用例跟我们的是否存在相似之处?你们喜欢Aerospike的实际表现吗?你们对Aerospike还有哪些不满?”等问题。在此之后,我们还非常关心“如果我将其引入自己的业务体系,是否会还出现什么意想不到的计划外状况?”
另一项评估元素则源自开发人员的偏好倾向。这一点在开源项目当中表现得尤为突出,不过在商业产品范畴内也极具指导意义。与此相关的问题包括:“是否已经有开发人员编写、使用以及为其创建文档?这款产品是否拥有我们想要的发展轨迹?我身边的朋友中是否有人正在使用这套系统?如果这是一套开源系统,那我是否需要独力解决自己面临的问题?”
举例来说,我们目前正在对Apache Storm与Apache Spark进行全面比较。这两个项目都能够作为实时计算处理系统的实用性解决手段,那么哪一种更受开发人员的青睐呢?在其它因素旗鼓相当的情况下,这一点就显得非常重要了。
接下来是适应性水平。换句话来说:这套方案能否顺畅融入我的系统?举例而言,如果我们目前所使用的是PHP、Python或者C++,那么这款新软件能否以原生方式集成到对应语言当中?我们又是否能够编写出切实与该组件内API相对接的工具?
除此之外,我们还要深入考量产品出现故障的可能性。特别是在我们的实际案例当中,企业的多座数据中心分布在全球各个位置,最重要的就是在故障出现时及时了解实际情况。某些产品在遭遇意外时不会发出警报作为提醒,这在我们眼中就显得非常危险。
最后一个需要考虑的问题在于平台的潜在风险——投入大量资源构建起的方案有可能在后续使用过程中给企业带来恐怖的额外成本。举例来说,如果一家企业并没有以.Net为核心构建业务体系的经验,那么选择任何一套与.Net相关的技术平台都将毫无意义。如果这套技术方案基于Java所打造,那么我们是否拥有对其加以妥善维护的必要资源?如果我们采用的是Amazon Web Services或者Google Compute Engine,那么是否有信心在未来三年内继续将全部业务依赖于这些云平台的发展趋势?
一家企业所采用的技术方案在潜在客户、合作伙伴或者投资者眼中往往会被视为优势或者劣势因素。总而言之,平台的实施目标在于贴合业务的运营目标,这也应该成为指导我们选择的根本性原则。
英文:http://www.infoworld.com/article/2868513/database/how-to-serve-billion-web-requests-per-day.html
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































