
非主流node.js异步转同步
异步转同步方案分类
说起nodejs的异步转同步,估计大家不陌生。因为nodejs回调实在太多了,稍微复杂一点的程序就会有很多层的回调嵌套。为了处理这些令人抓狂的回调,我们一般需要使用一些框架或工具将这些异步过程转换成相对比较容易理解的同步过程,也就是我们本文所说的异步转同步。而完成这种转换的工具或库大体上可以分为三类:1. 回调链管理类 2. 编译工具类 3. 底层实现修改类。
第一类是最工具常见的,以Promise、async为代表。这类工具一般需要调用一个方法将我们
的处理函数包裹然后进行链式调用,比如如下使用Promise的代码
function readJSON(filename){
return new Promise(function (fulfill, reject){
readFile(filename, ‘utf8‘).done(function (res){
try {
fulfill(JSON.parse(res));
} catch (ex) {
reject(ex);
}
}, reject);
});
}
readJSON.then(doOthers);
因为nodejs是一个以回调来驱动的编程框架,回调是框架中的主旋律。而第一类工具也是使用回调来处理问题的,因此我们暂且称第一类工具属于“nodejs异步转同步的主流方法“。这就好比在一个重视宗教的社会中,采用教义来化解矛盾会被大家普遍接受是一样的道理。
第二类工具与第一类类似,也是通过管理回调来实现的,但省去了格式上的要求,通过编译程序自动完成转换。这类工具都程序员要更友好一些,但付出的代价就是代码必须编译,而编译后的代码可能非常晦涩难懂。这一类工具用的也不少,但相比第一类来说稍微小众了些,但因为原理上还是使用回调来解决的问题,所以我们说这一类工具也还算在主流方法之内。
上面的两种主流的解决方案在这种场景下是适用的:代码的整体执行流程是自己可控的。即你自己可以决定将整个执行流程写成
do_task1();
do_task2();
do_task3();
也可以将整个执行流程写成
do_task1()
.then(do_task2)
.then(do_task3)
但如果代码的整体执行流程自己不可控呢?会有这样的场景?好,考虑下下面的场景。假设你需要对外提供一个js sdk给客户,我们暂且称这个SDK为foo, 其中有一个方法: foo.getUserList(String: id)。不管是你自己当时设计的时候脑子不小心被门挤了一下,或者是你倒霉的前任故意留坑想整你,总之这个接口设计的时候根本就没有考虑有异步的情况,那个方法就只用一种同步使用方法。用户一直是这么使用的
var usrs = foo.getUserList(id);
renderUserList(usrs);
突然有一天业务调整了,原本需要从文件中读取的数据需要从网络读取了,而nodejs中所有的网络请求都是异步的,其你又不能立即强制用户去修改他们的代码。这时候你如何去重构这个方法的实现呢?如果你觉得这个离你还比较遥远那么考虑下这种你更可能遇到的情况。你正在使用某个库去处理某种格式的文件,而这个库为了增强扩展性允许用户去为其扩展支持的函数,假设扩展语法如下
foo.regFn(‘getUrl‘, function(args){
})
而这个倒霉的库内部是这样调用你扩展的方法的
var fnVal = this[fnName]([fnProp1, fnProp2]);
output(fnVal);
而更倒霉的是你必须要发起一个异步请求并等待请求返回之后才能函数的返回值返回。这种情况你如何处理呢?对于这种极端的场景上面提到的两种主流解决方案是解决不了的,必须使用非主流且更底层的解决方案,也就是本文所重点介绍的方案3.
非主流解决方案
之所以将方案3称为非主流方案,有两个原因:1. 使用的场景非主流,比较极端. 2. 库使用的开发语言非主流(针对nodejs开发而言),不是Javascript而是C++。 为什么需要C++来实现呢?我们一会再说,先通过一段代码看下非主流解决方案的效果。在此样例代码中我们使用了deasync库。类似的库还有fibers,以及es6中引入的yield, 但这两者都有局限只能阻塞一部分代码的执行,并不能阻塞整个JS引擎的执行。
var http = require(‘http‘);
var deasync = require(‘deasync‘);
var get_http_status = function(url){
var status, isReturn = false;
http.get(url, function(res){
console.log(‘http request return!‘);
isReturn = true;
status = res.statusCode;
});
while(!isReturn){
deasync.runLoopOnce();
}
return status;
}
var reqUrl = ‘http://www.taobao.com‘;
console.log(‘begin to request: %s‘, reqUrl);
console.log(‘http respons status is: %s‘, get_http_status(reqUrl));
console.log(‘programe end‘);
deasync native 代码
#include <node.h>
#include <v8.h>
using namespace v8;
uv_idle_t idler;
static void crunch_away(uv_idle_t* handle, int status) {
uv_idle_stop(handle);
}
static Handle<Value> Run(const Arguments& args) {
HandleScope scope;
uv_idle_start(&idler, crunch_away);
// 注意这里的参数与nodejs的Start函数中的不一样,
// Start中是UV_RUN_DEFAULT是不停的在执行,而
// 这里只执行了一次。
uv_run(uv_default_loop(), UV_RUN_ONCE);
return scope.Close(Undefined());
}
static void Init(Handle<Object> target) {
node::SetMethod(target, "run", Run);
uv_idle_init(uv_default_loop(), &idler);
}
NODE_MODULE(deasync, Init)
可以看到上面的代码成功的实现了阻塞程序的执行直到异步函数返回, 从而实现了异步转同步的目的。很神奇吧?为什么那段代码可以顺序执行而不会被死循环卡死,为什么类似库需要用C++开发?要解答这些问题需要从nodejs框架的内部工作流程说起。
我们先大致看下某nodejs的初始化代码(来自网络,经校队与最新版本代码大致一致,省去了部分选择编译部分以及assert部分)
int Start(int argc, char *argv[]) {
// This needs to run *before* V8::Initialize()
// Use copy here as to not modify the original argv:
Init(argc, argv_copy);
V8::Initialize();
{
// Create all the objects, load modules, do everything.
// so your next reading stop should be node::Load()!
Load(process_l);
// All our arguments are loaded. We‘ve evaluated all of the scripts. We
// might even have created TCP servers. Now we enter the main eventloop. If
// there are no watchers on the loop (except for the ones that were
// uv_unref‘d) then this function exits. As long as there are active
// watchers, it blocks.
uv_run(uv_default_loop(), UV_RUN_DEFAULT);
EmitExit(process_l);
RunAtExit();
}
return 0;
}
因为uv_run的代码量实在太大了,因此我们借用下@朴灵书中的一张流程图来说明整个流程
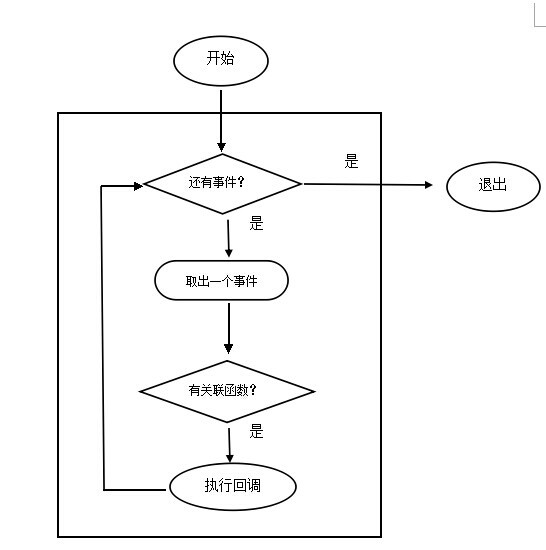
从上面的初始化代码并结合nodejs支持异步的特性,我们可以得出如下结论:
- node启动之后先加载并执行通过命令制定的JS文件然后执行事件循环。
- 执行JS代码的脚本引擎和事件循环检查位于同一个线程之内
- IO操作应该运行于主线程之外的独立线程中,否则单线程没必要扫描,都是自己做,完成之后可以立即执行回调。
好了有了上述几条结论之后我们来分析下上面那段异步转同步的示例代码。
- nodejs启动之后初始化v8执行环境, 之后加载并运行样例代码。
- 样例代码中发起http请求并制定回调函数
- nodejs响应js的调用,并创建一线程来发送http请求,并向事件循环检查链表末端追加一个检查项。检查项 中记录该项目对应的IO线程以及对应的回调。
- v8引擎继续执行脚本,进入循环并调用deasync.runLoopOnce()
- 因为deasync执行对应的native程序,强制nodejs遍历一遍事件循环检查链表看网络请求是否完成,若完成 执行回调。
- v8引擎继续执行脚本继续执行循环,直到异步返回并执行回调。
- 程序整体执行完毕后退出
因此native代码强迫nodejs遍历一遍事件循环检查链表是整个程序能够运行的关键。因为进入循环的时候JS代码还没有运行完毕,而nodejs的事件循环部分尚未开始,即使异步的网络请求有返回了也没有机会执行回调。因此类似的库只有C++才能开发,因为只有C++代码才有访问nodejs底层函数的能力。
非主流有就是非主流,有不良后果,请谨慎使用!
通过上面的分析我们基本清楚了整个代码的总体执行流程。这类非主流库通过使用native代码对nodejs底层代码的执行流程做了调整,从而达到了正常手段无法达到的效果。但这个过程实际上对nodejs的执行是一个干扰,就像我们伪造了证件或走后门进入了一个组织的内部,虽然外面看上去是进去了,貌似从原理上来说也没什么纰漏,但非正常终归是非正常,很难说什么时候会出问题。
我很不幸麻烦很快就遇到了。当我开发grunt-myless的时候成功的用这个方案实现了异步转同步,并且测试用例运行的也很好。但当我将代码以grunt插件的形式运行的时候,诡异的问题出现了:所有的网络相关的异步请求都被阻塞了,而其他类型的异步请求正常! 至于原因我暂时不知道,我实在没有勇气去调试一个多线程的系统,而且还是那么复杂的一个系统。但我可以告诉你一个 中医式的解决方案:
- 创建一个子进程来运行你的网络操作代码,将操作结果通过命令行来输出。
- 阻塞代码执行直到命令结果返回。
- 解析命令行文本为对象。具体实现请懒得贴了
请自己参考grunt-myless中/src/util/net/exec.js
感想和鸣谢
这篇文章犹豫了很久要不要写。一是因为我没有怎么读过nodejs的源码实现,很难把各种的缘由说清楚。二是因为文中提到的技巧怎么来说都算不上最优的解决方案,甚至有点旁门左道的味道,弄不好会出现解决一个小问题但弄出更大的问题导致整个系统不能用。但后来一想在特殊的场景下这似乎又是唯一的解决方案,至少我想不出更好的解决方案,自己当初研究半天就这么丢掉又有点舍不得。所以最终还是决定把此文完成,也许某人也像我一样被某种极端情况逼到绝境,如果那样,最起码这篇文章能让他们不至于立即死掉。最后多谢@朴灵不厌其烦的解答各种nodejs底层实现问题
参考、引用列表
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































