
百分点内存数据库架构演变
【2014中国数据库技术大会】内存计算:百分点内存数据库架构演变
【IT168数据库大会现场报道】2014年4月10日-12日,第五届中国数据库技术大会(DTCC 2014)在北京五洲皇冠国际酒店拉开序幕。在为期三天的会议中,大会将围绕大数据应用、数据架构、数据管理、传统数据库软件等技术领域展开深入探讨,并将邀请一批国内顶尖的技术专家来进行分享。本届大会将在保留数据库软件应用实践这一传统主题的基础上,向大数据、数据结构、数据治理与分析、商业智能等领域进行拓展,以满足于广大从业人士和行业用户的迫切需要。

自2010年以来,国内领先的IT专业网站IT168联合旗下ITPUB、ChinaUnix两大技术社区,已经连续举办了四届中国数据库技术大会,每届大会与会规模超千人,大会云集了国内水平最高的数据架构师、数据库管理和运维工程师、数据库开发工程师、研发总监和IT经理等技术人群,是目前国内最受欢迎、人气最高的的数据库技术交流盛会。今年是中国数据库技术大会五周年,大会将继续秉承分享IT最佳应用实践的宗旨,围绕传统数据库和大数据两条技术主线,在目前IT技术和管理快速的大背景下,更加深入地探讨数据库技术的现状和未来的发展方向,以及我们在这个转型过程中的实践经验和教训。
今天是DTCC大会第二天,在专场3中,来自百分点的高级架构师武毅给我们带来了《百分点内存数据库架构演变》的精彩分享。

▲武毅:百分点高级架构师
如今数据不再昂贵,但从海量数据中获取价值变得昂贵,而要及时获取价值则更加昂贵,这正是大数据实时计算越来越流行的原因。在当今互联网时代,对海量数据的实时计算成为可能。
武毅谈到,现在内存计算的5大趋势:1、数据展现上,时间就是金钱。2、面临着处理海量的数据。3、磁盘IO成为并行计算的瓶颈。4、针对不同行业,应对各种业务需求,需要从不同的维度去处理,分析数据。5、对内存数据库的需求。
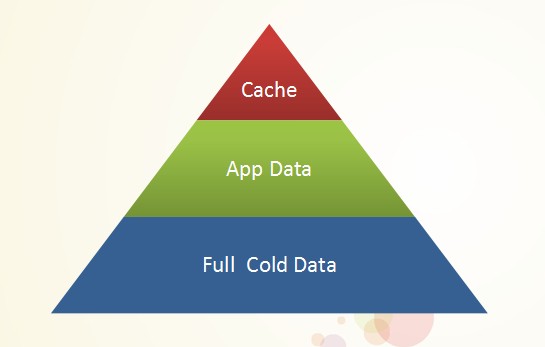
互联网公司数据金字塔
百分点推荐引擎中,需要在几百毫秒内,从海量的数据中获取针对当前用户的个性化的推荐结果。传统的RDB+memcache的方式显然已经无法满足,只有全内存计算才能如此高效。推荐引擎系统等应用极大的依赖内存数据库,对于内存数据库的数据可靠性,高可用性,数据一致性都有较高的要求。在不同的应用场景下对内存数据库的要求也会有较大差异。经历几次架构变迁之后,平台级内存数据库趋于稳定。
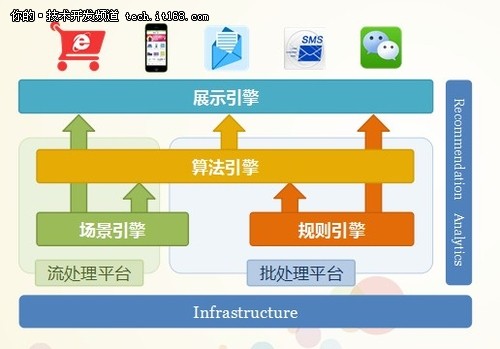
▲百分点推荐引擎BRE的框架原理
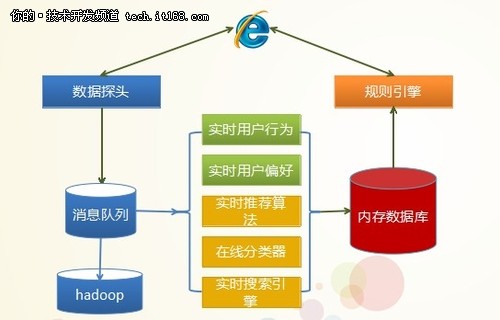
▲BRE实时计算:lambda架构示意

▲BRE基于内存数据库的实时计算
内存数据库是BRE的主存
1、数据实时更新:用户行为、用户偏好、商品资讯信息、推荐算法结果、集群监控数据…
2、海量数据:十几种类别、十亿量级条目数、TB量级存储量
3、高并发、高吞吐量:每秒十万量级读写次数、GB量级数据量
4、高可靠和高可用:数据固化、容灾、备份
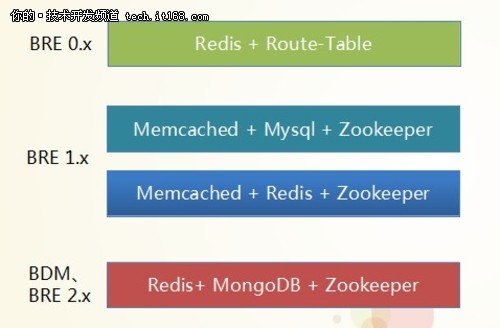
▲百分点内存数据库演变,展现了应用技术的变化
BRE 0.x的内存数据库的局限:需要手工维护路由表、容易导致负载不均衡、人工成本高扩展性较差。
BRE 1.x的内存数据库的局限:
1、Memcached不能作为数据库:无法固化数据、无法枚举数据、无法很好的控制数据过期
2、读写分离导致系统复杂
3、简单的KV不能满足需求:大Value导致网卡瓶颈
数据序列化/反序列化消耗系统资源
4、扩容不易:虚结点的使用导致需要重新计算所有数据分布
BDM的内存数据库:最终一致性
1、读写异步模型(lambda架构)
2、Master 挂掉,此时还未同步到Slave的数据(从消息队列中回放数据恢复;算法数据再生,持续输出;Slave升级为Master,原Master恢复后作为Slave)
3、Slave挂掉,恢复后数据重新同步
小结:
百分点内存数据库包括了实时计算框架和数据查询框架,的系统架构、处理流程和应用。 重点介绍了百分点推荐引擎BRE的框架原理,BRE基于内存数据库的实时计算,在百分点公司在实时计算算法中常用的方法和技巧,框架的演进。通过不断的提高实时计算的数据规模和处理效率,帮助业务快速发展。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































