
一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
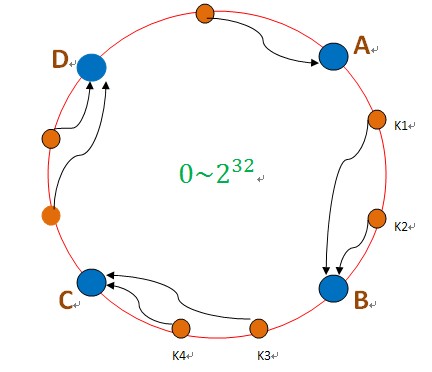
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
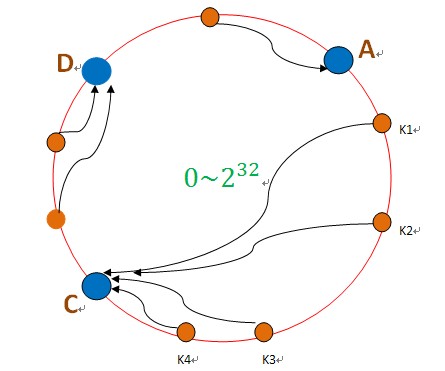
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
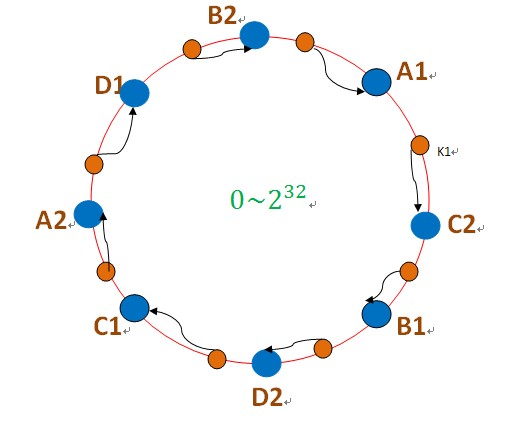
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82 |
public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等 private
TreeMap<Long, S> nodes; // 虚拟节点 private
List<S> shards; // 真实机器节点 private
final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数 public
Shard(List<S> shards) { super(); this.shards = shards; init(); } private
void init() { // 初始化一致性hash环 nodes = new
TreeMap<Long, S>(); for
(int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点 final
S shardInfo = shards.get(i); for
(int n = 0; n < NODE_NUM; n++) // 一个真实机器节点关联NODE_NUM个虚拟节点 nodes.put(hash("SHARD-"
+ i + "-NODE-"
+ n), shardInfo); } } public
S getShardInfo(String key) { SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点 if
(tail.size() == 0) { return
nodes.get(nodes.firstKey()); } return
tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息 } /** * MurMurHash算法,是非加密HASH算法,性能很高, * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免) * 等HASH算法要快很多,而且据说这个算法的碰撞率很低. */ private
Long hash(String key) { ByteBuffer buf = ByteBuffer.wrap(key.getBytes()); int
seed = 0x1234ABCD; ByteOrder byteOrder = buf.order(); buf.order(ByteOrder.LITTLE_ENDIAN); long
m = 0xc6a4a7935bd1e995L; int
r = 47; long
h = seed ^ (buf.remaining() * m); long
k; while
(buf.remaining() >= 8) { k = buf.getLong(); k *= m; k ^= k >>> r; k *= m; h ^= k; h *= m; } if
(buf.remaining() > 0) { ByteBuffer finish = ByteBuffer.allocate(8).order( ByteOrder.LITTLE_ENDIAN); // for big-endian version, do this first: // finish.position(8-buf.remaining()); finish.put(buf).rewind(); h ^= finish.getLong(); h *= m; } h ^= h >>> r; h *= m; h ^= h >>> r; buf.order(byteOrder); return
h; }} |
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。




































