
空间向量模型lucene
把一篇文档看作是一系列词元的集合,每个词元都有一个权重,如下:
Document A= {termX, termY, termZ …… termN}
Document B= {termX, termY, termZ …… termN}
DocumentVector = {weight1, weight2, weight3 …… weightN}
weigh为每个分词的映射到单位矩阵的,长度。这样就把文档放到一个N维的空间向量中(矩阵)【所有文档分成N个词元,就N维向量矩阵;其中文档D在m坐标上的映射为文档D中的m词元的权重】得到向量坐标系,对文档信息的检索,就转化为求两个向量之间的夹角大小
余弦相似性是通过测量两个向量内积空间的夹角的余弦值来判定两个向量之间的相似程度。余弦值越接近1,其夹角越接近0,表示两个向量越相似。如图:

两个向量间的余弦值可以根据欧几里得点积和量级公式推导: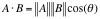 (9)
(9)
由式(9)以及理论,我们可以得出: (10)
(10)
通过计算查询向量与每一个向量的夹角余弦值就可得到该查询字符串与索引中的记录的相关度 。
查询词后面加^N来设定此查询词的权重,默认是1,如果N大于1,则说明此查询词更重要,如果N小于1,则说明此查询词更不重要。^N代表每个词在矩阵中的长度大小。(用矩阵代表坐标,是为了个人扩展思路,给个传送门http://blog.csdn.net/myan/article/details/1865397)
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。


































