
基于spark1.3.1的spark-sql实战-02
浏览数:43 /
时间:2015年06月12日
Hive Tables
将HIVE_HOME/conf/hive-site.xml 文件copy到SPARK_HOME/conf/下
When not configured by the hive-site.xml, the context automatically creates metastore_db and warehouse in the current directory.
// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")sqlContext.sql("LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt‘ INTO TABLE src")// Queries are expressed in HiveQLsqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
JDBC To Other Databases

加载mysql数据库:test,表:t_user_new返回DataFrame
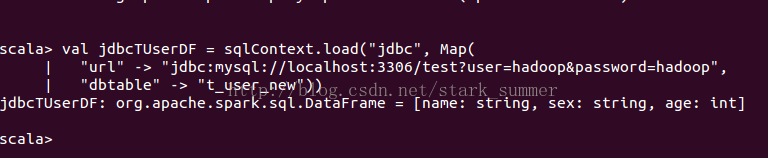
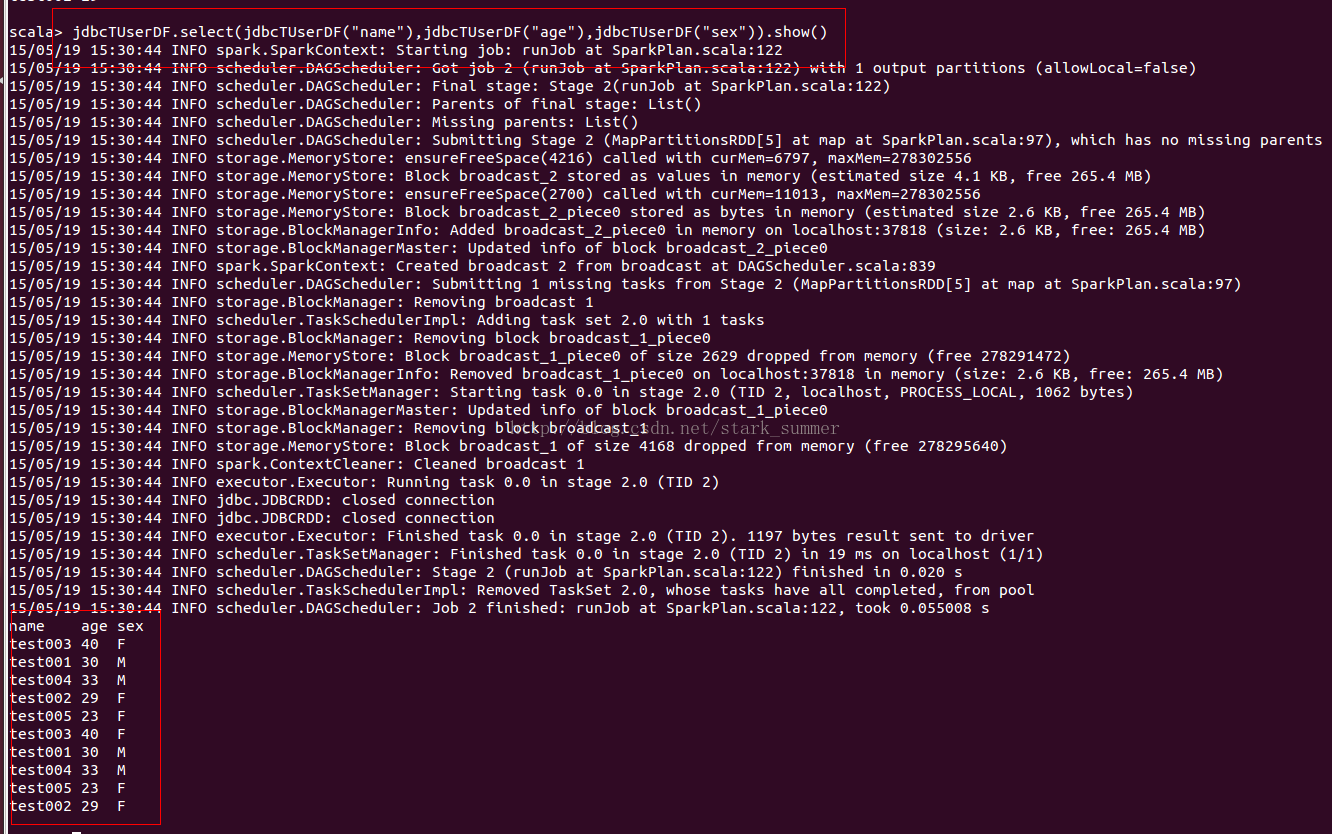
查询数据:
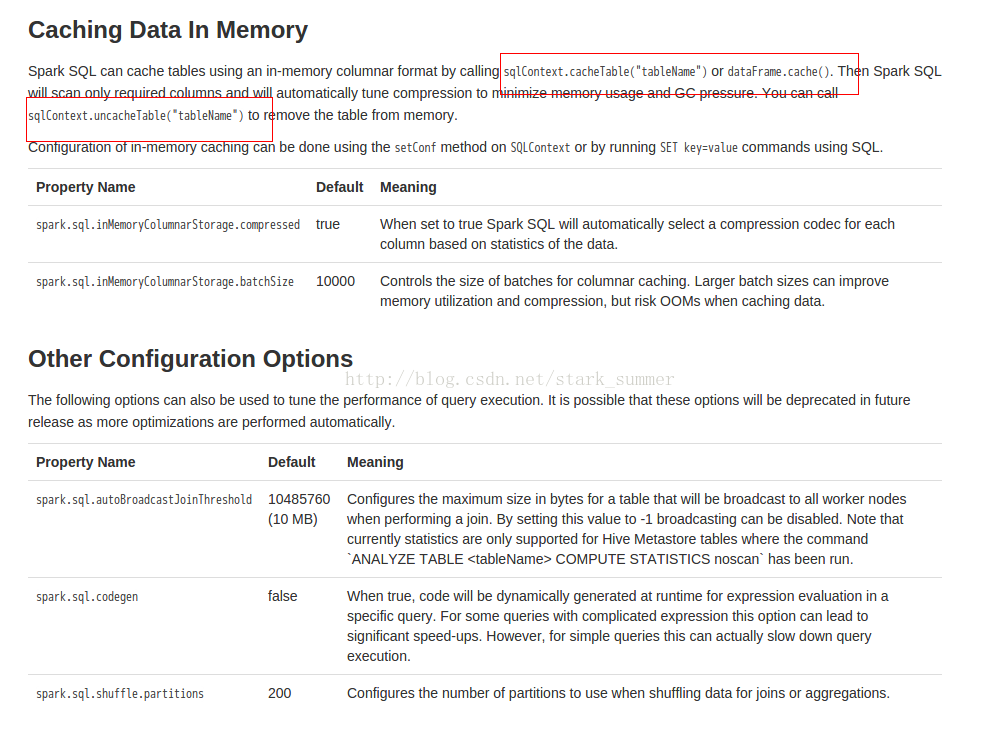
Performance Tuning
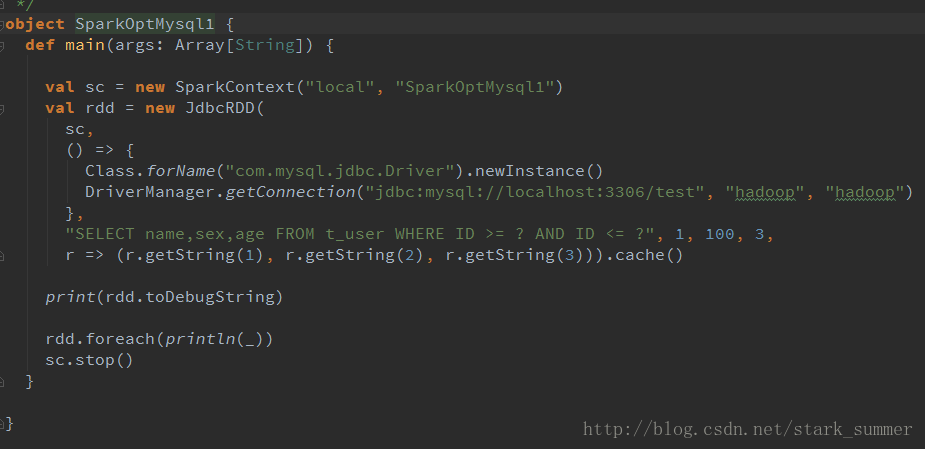
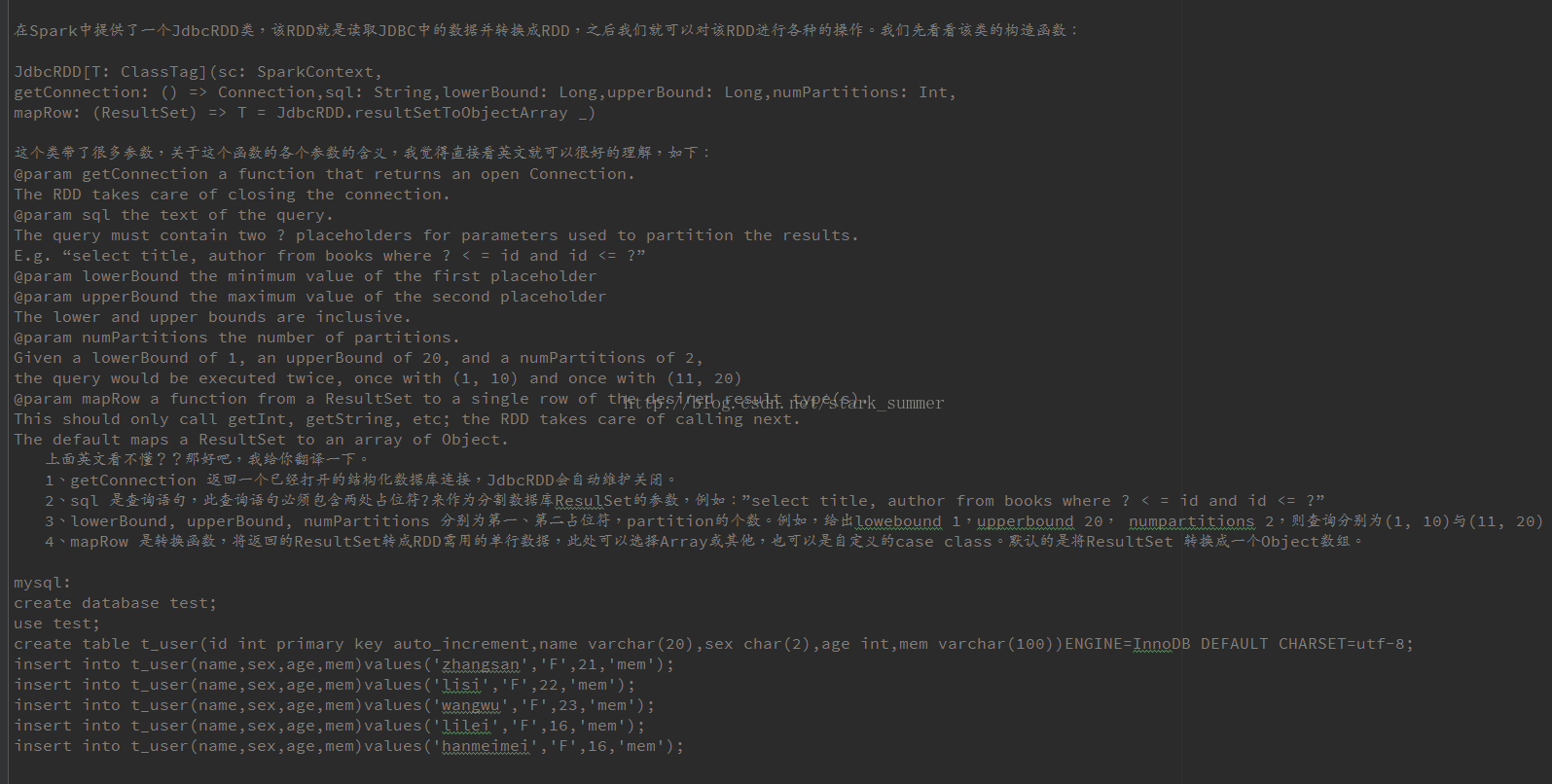
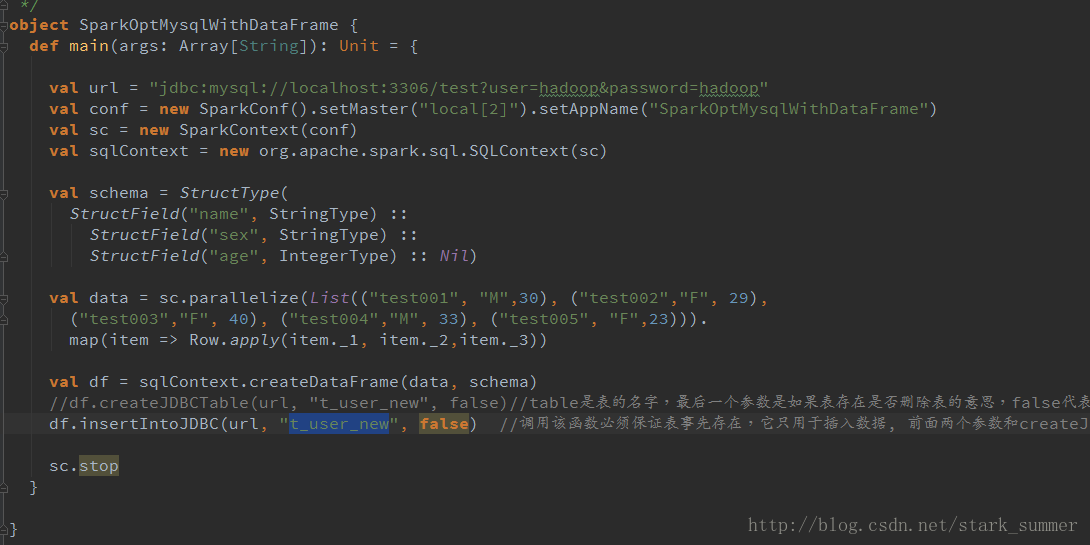
spark 程序操作JDBC:



未完待续~~~
尊重原创,未经允许不得转载:http://blog.csdn.net/stark_summer/article/details/45843803
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。

































