
PHP函数的实现原理及性能分析
作者:HDK (百度)
前言
在任何语言中,函数都是最基本的组成单元。对于php的函数,它具有哪些特点?函数调用是怎么实现的?php函数的性能如何,有什么使用建议?本文将从原理出发进行分析结合实际的性能测试尝试对这些问题进行回答,在了解实现的同时更好的编写php程序。同时也会对一些常见的php函数进行介绍。
php函数的分类
在php中,横向划分的话,函数分为两大类: user function(内置函数) 和internal function(内置函数)。前者就是用户在程序中自定义的一些函数和方法,后者则是php本身提供的各类库函数(比如sprintf、array_push等)。用户也可以通过扩展的方法来编写库函数,这个将在后面介绍。对于user function,又可以细分为function(函数)和method(类方法),本文中将就这三种函数分别进行分析和测试。
php函数的实现
一个php函数最终是如何执行,这个流程是怎么样的呢?
要回答这个问题,我们先来看看php代码的执行所经过的流程。
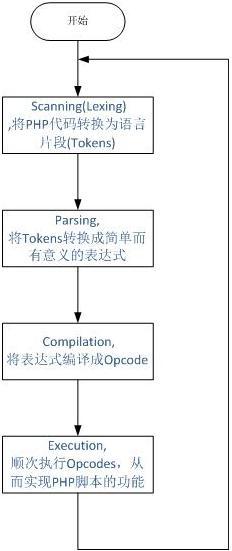
从图1可以看到,php实现了一个典型的动态语言执行过程:拿到一段代码后,经过词法解析、语法解析等阶段后,源程序会被翻译成一个个指令(opcodes),然后ZEND虚拟机顺次执行这些指令完成操作。Php本身是用c实现的,因此最终调用的也都是c的函数,实际上,我们可以把php看做是一个c开发的软件。
通过上面描述不难看出,php中函数的执行也是被翻译成了opcodes来调用,每次函数调用实际上是执行了一条或多条指令。
对于每一个函数,zend都通过以下的数据结构来描述
typedef union _zend_function {
zend_uchar type; /* MUST be the first element of this struct! */
struct {
zend_uchar type; /* never used */
char *function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
zend_bool pass_rest_by_reference;
unsigned char return_reference;
} common;
zend_op_array op_array;
zend_internal_function internal_function;
} zend_function;
typedef struct _zend_function_state {
HashTable *function_symbol_table;
zend_function *function;
void *reserved[ZEND_MAX_RESERVED_RESOURCES];
} zend_function_state;
其中type标明了函数的类型:用户函数、内置函数、重载函数。Common中包含函数的基本信息,包括函数名,参数信息,函数标志(普通函数、静态方法、抽象方法)等内容。另外,对于用户函数,还有一个函数符号表,记录了内部变量等,这个将在后面详述。 Zend维护了一个全局function_table,这是一个大的hahs表。函数调用的时候会首先根据函数名从表中找到对应的zend_function。当进行函数调用时候,虚拟机会根据type的不同决定调用方法, 不同类型的函数,其执行原理是不相同的 。
内置函数
内置函数,其本质上就是真正的c函数,每一个内置函数,php在最终编译后都会展开成为一个名叫zif_xxxx的function,比如我们常见的sprintf,对应到底层就是zif_sprintf。Zend在执行的时候,如果发现是内置函数,则只是简单的做一个转发操作。
Zend提供了一系列的api供调用,包括参数获取、数组操作、内存分配等。内置函数的参数获取,通过zend_parse_parameters方法来实现,对于数组、字符串等参数,zend实现的是浅拷贝,因此这个效率是很高的。可以这样说,对于php内置函数,其效率和相应c函数几乎相同,唯一多了一次转发调用。
内置函数在php中都是通过so的方式进行动态加载,用户也可以根据需要自己编写相应的so,也就是我们常说的扩展。ZEND提供了一系列的api供扩展使用
用户函数
和内置函数相比,用户通过php实现的自定义函数具有完全不同的执行过程和实现原理。如前文所述,我们知道php代码是被翻译成为了一条条opcode来执行的,用户函数也不例外,实际中每个函数对应到一组opcode,这组指令被保存在zend_function中。于是,用户函数的调用最终就是对应到一组opcodes的执行。
- 局部变量的保存及递归的实现
我们知道,函数递归是通过堆栈来完成的。在php中,也是利用类似的方法来实现。Zend为每个php函数分配了一个活动符号表(active_sym_table),记录当前函数中所有局部变量的状态。所有的符号表通过堆栈的形式来维护,每当有函数调用的时候,分配一个新的符号表并入栈。当调用结束后当前符号表出栈。由此实现了状态的保存和递归。
对于栈的维护,zend在这里做了优化。预先分配一个长度为N的静态数组来模拟堆栈,这种通过静态数组来模拟动态数据结构的手法在我们自己的程序中也经常有使用,这种方式避免了每次调用带来的内存分配、销毁。ZEND只是在函数调用结束时将当前栈顶的符号表数据clean掉即可。
因为静态数组长度为N,一旦函数调用层次超过N,程序不会出现栈溢出,这种情况下zend就会进行符号表的分配、销毁,因此会导致性能下降很多。在zend里面,N目前取值是32。因此,我们编写php程序的时候,函数调用层次最好不要超过32。当然,如果是web应用,本身可以函数调用层次的深度。
- 参数的传递
和内置函数调用zend_parse_params来获取参数不同,用户函数中参数的获取是通过指令来完成的。函数有几个参数就对应几条指令。具体到实现上就是普通的变量赋值。
通过上面的分析可以看出,和内置函数相比,由于是自己维护堆栈表,而且每条指令的执行也是一个c函数,用户函数的性能相对会差很多,后面会有具体的对比分析。因此,如果一个功能有对应php内置函数实现的尽量不要自己重新写函数去实现。
类方法
类方法其执行原理和用户函数是相同的,也是翻译成opcodes顺次调用。类的实现,zend用一个数据结构zend_class_entry来实现,里面保存了类相关的一些基本信息。这个entry是在php编译的时候就已经处理完成。
在zend_function的common中,有一个成员叫做scope,其指向的就是当前方法对应类的zend_class_entry。关于php中面向对象的实现,这里就不在做更详细的介绍,今后将专门写一篇文章来详述php中面向对象的实现原理。就函数这一块来说,method实现原理和function完全相同,理论上其性能也差不多,后面我们将做详细的性能对比。
性能对比
函数名长度对性能的影响
- 测试方法
对名字长度为1、2、4、8、16的函数进行比较,测试比较它们每秒可执行次数,确定函数名长度对性能的影响
- 测试结果如下图
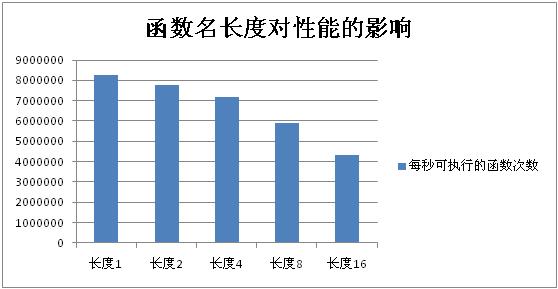
- 结果分析
从图上可以看出,函数名的长度对性能还是会有一定的影响。一个长度为1的函数和长度为16的 空函数调用 ,其性能差了1倍。分析一下源码不难找到原因,如前面叙述所说,函数调用的时候zend会先在一个全局的funtion_table中通过函数名查询相关信息,function_table是一个哈希表。必然的,名字越长查询所需要的时间就越多。 因此,在实际编写程序的时候,对多次调用的函数,名字建议不要太长
虽然函数名长度对性能有一定影响,但具体有多大呢?这个问题应该还是需要结合实际情况来考虑,如果一个函数本身比较复杂的话,那么对整体的性能影响并不大。
一个建议是对于那些会调用很多次,本身功能又比较简单的函数,可以适当取一些言简意赅的名字。
函数个数对性能的影响
- 测试方法
在以下三种环境下进行函数调用测试,分析结果:1.程序仅包含1个函数 2.程序包含100个函数 3.程序包含1000个函数。
测试这三种情况下每秒所能调用的函数次数
- 测试结果如下图
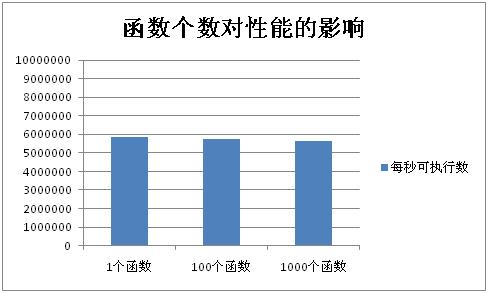
- 结果分析
从测试结果可以看出,这三种情况下性能几乎相同,函数个数增加时性能下降微乎其微,可以忽略。
从实现原理分析,几种实现下唯一的区别在于函数获取的部分。如前文所述,所有的函数都放在一个hash表中,在不同个数下查找效率都应该还是接近于O(1),所以性能差距不大。
不同类型函数调用消耗
- 测试方法
选取用户函数、类方法、静态方法、内置函数各一种,函数本身不做任何事情,直接返回,主要测试空函数调用的消耗。测试结果为每秒可执行次数
测试中为去除其他影响,所有函数名字长度相同
- 测试结果如下图
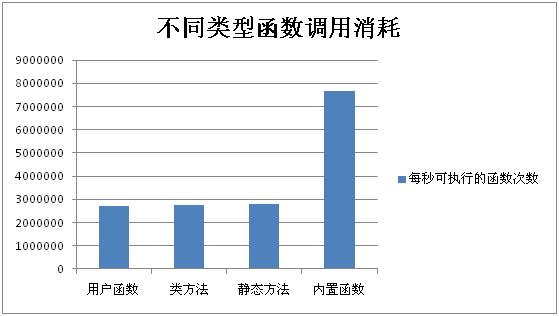
- 结果分析
通过测试结果可以看到,对于用户自己编写的php函数,不管是哪种类型,其效率是差不多的,均在280w/s左右。如我们预期,即使是空调,内置函数其效率也要高很多,达到780w/s,是前者是3倍。可见,内置函数调用的开销还是远低于用户函数。从前面原理分析可知主要差距在于用户函数调用时初始化符号表、接收参数等操作。
内置函数和用户函数性能对比
- 测试方法
内置函数和用户函数的性能对比,这里我们选取几个常用的函数,然后用php实现相同功能的函数进行一下性能对比。
测试中,我们选取字符串、数学、数组中各一个典型进行对比,这几个函数分别是字符串截取(substr)、10进制转2进制(decbin)、求最小值(min)和返回数组中的所以key(array_keys)。
- 测试结果如下图
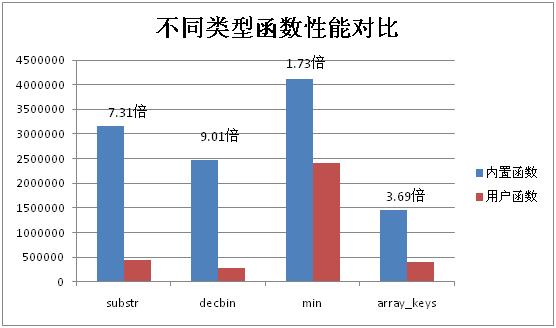
- 结果分析
从测试结果可以看出,如我们预期,内置函数在总体性能上远高于普通用户函数。尤其对于涉及到字符串类操作的函数,差距达到了1个数量级。因此,函数使用的一个原则就是如果某功能有相应的内置函数,尽量使用它而不是自己编写php函数。
对于一些涉及到大量字符串操作的功能,为提高性能,可以考虑用扩展来实现。比如常见的富文本过滤等。
和C函数性能对比
- 测试方法
我们选取字符串操作和算术运算各3种函数进行比对,php用扩展实现。三种函数是简单的一次算法运算、字符串比较和多次的算法运算。
除了本身的两类函数外,还会测试将函数空调开销去掉后的性能,一方面比对一下两种函数(c和php内置)本身的性能差异,另外就是侧面印证空调函数的消耗
测试点为执行10w次操作的时间消耗
- 测试结果如下图
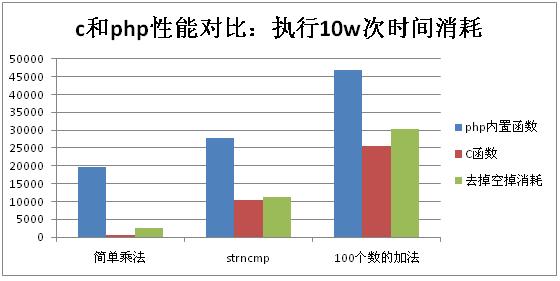
- 结果分析
内置函数和C函数的开销在去掉php函数空调用的影响后差距较小,随着函数功能越来越复杂,双方性能趋近于相同。这个从之前的函数实现分析中也容易得到论证,毕竟内置函数就是C实现的。
函数功能越复杂,c和php的性能差距越小
相对c来说,php函数调用的开销大很多,对于简单函数来说性能还是有一定影响。因此php中函数不宜嵌套封装太深。
伪函数及其性能
在php中,有这样一些函数,它们在使用上是标准的函数用法,但底层实现却和真正函数调用完全不同,这些函数不属于前文提到的三种function中的任何一类,其实质是一条单独的opcode,这里估且叫做伪函数或者指令函数。
如上所说,伪函数使用起来和标准的函数并无二致,看起来具有相同的特征。但是他们最终执行的时候是被zend反映成了一条对应的指令(opcode)来调用,因此其实现更接近于if、for、算术运算等操作。
- php中的伪函数
isset
empty
unset
eval
通过上面的介绍可以看出,伪函数由于被直接翻译成指令来执行,和普通函数相比少了一次函数调用所带来的开销,因此性能会更好一些。我们通过如下测试来做一个对比。 Array_key_exists和isset两者都可以判断数组中某个key是否存在,看一下他们的性能
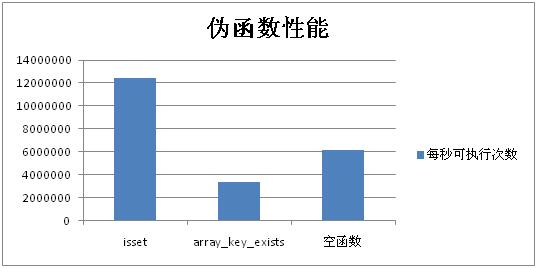
从图上可以看出,和array_key_exists相比,isset性能要高出很多,基本是前者的4倍左右,而即使是和空函数调用相比,其性能也要高出1倍左右。由此也侧面印证再次说明了php函数调用的开销还是比较大的。
常用php函数实现及介绍
count
count是我们经常用到的一个函数,其功能是返回一个数组的长度。
count这个函数,其复杂度是多少呢?
一种常见的说法是count函数会遍历整个数组然后求出元素个数,因此复杂度是O(n)。那实际情况是不是这样呢?
我们回到count的实现来看一下,通过源码可以发现,对于数组的count操作,函数最终的路径是zif_count->
php_count_recursive-> zend_hash_num_elements,而zend_hash_num_elements的行为是
return
ht->nNumOfElements,可见,这是一个O(1)而不是O(n)的操作。实际上,数组在php底层就是一个hash_table,对于hash表,zend中专门有一个元素nNumOfElements记录了当前元素的个数,因此对于一般的count实际上直接就返回了这个值。由此,我们得出结论: count是O(1)的复杂度,和具体数组的大小无关。
非数组类型的变量,count的行为时怎样?
对于未设置变量返回0,而像int、double、string等则会返回1
strlen
Strlen用于返回一个字符串的长度。那么,他的实现原理是如何的呢?
我们都知道在c中strlen是一个o(n)的函数,会顺序遍历字符串直到遇到/0,然后出长度。Php中是否也这样呢?答案是否定的,php里字符串是用一个复合结构来描述,包括指向具体数据的指针和字符串长度(和c++中string类似),因此strlen就直接返回字符串长度了,是常数级别的操作。
另外,对于非字符串类型的变量调用strlen,它会首先将变量强制转换为字符串再求长度,这点需要注意。
isset和array_key_exists
这两个函数最常见的用法都是判断一个key是否在数组中存在。但是前者还可以用于判断一个变量是否被设置过。
如前文所述,isset并非真正的函数,因此它的效率会比后者高很多。推荐用它代替array_key_exists。
array_push和array[]
两者都是往数组尾部追加一个元素。不同的是前者可以一次push多个。他们最大的区别在于一个是函数一个是语言结构,因此后者效率要更高。因此如果只是普通的追加元素,建议使用array []。
rand和mt_rand
两者都是提供产生随机数的功能,前者使用libc标准的rand。后者用了 Mersenne Twister
中已知的特性作为随机数发生器,它可以产生随机数值的平均速度比 libc 提供的 rand()
快四倍。因此如果对性能要求较高,可以考虑用mt_rand代替前者。
我们都知道,rand产生的是伪随机数,在C中需要用srand显示指定种子。但是在php中,rand会自己帮你默认调用一次srand,一般情况下不需要自己再显示的调用。
需要注意的是,如果特殊情况下需要调用srand时,一定要配套调用。就是说srand对于rand,mt_srand对应srand,切不可混合使用,否则是无效的。
sort和usort
两者都是用于排序,不同的是前者可以指定排序策略,类似我们C里面的qsort和C++的sort。
在排序上两者都是采用标准的快排来实现,对于有排序需求的,如非特殊情况调用php提供的这些方法就可以了,不用自己重新实现一遍,效率会低很多。原因见前文对于用户函数和内置函数的分析比对。
urlencode和rawurlencode
这两个都是用于url编码, 字符串中除了 -_.
之外的所有非字母数字字符都将被替换成百分号(%)后跟两位十六进制数。两者唯一的区别在于对于空格,urlencode会编码为+,而rawurlencode会编码为%20。
一般情况下除了搜索引擎,我们的策略都是空格编码为%20。因此采用后者的居多。
注意的是encode和decode系列一定要配套使用。
strcmp系列函数
这一系列的函数包括strcmp、strncmp、strcasecmp、strncasecmp,实现功能和C函数相同。但也有不同,由于php的字符串是允许/0出现,因此在判断的时候底层使用的是memcmp系列而非strcmp,理论上来说更快。
另外由于php直接能获取到字符串长度,因此会首先这方面的检查,很多情况下效率就会高很多了。
is_int和is_numeric
这两个函数功能相似又不完全相同,使用的时候一定需要注意他们的区别。
Is_int:判断一个变量类型是否是整数型,php变量中专门有一个字段表征类型,因此直接判断这个类型即可,是一个绝对O(1)的操作
Is_numeric:判断一个变量是否是整数或数字字符串,也就是说除了整数型变量会返回true之外,对于字符串变量,如果形如”1234”,”1e4”等也会被判为true。这个时候会遍历字符串进行判断。
总结及建议
通过对函数实现的原理分析和性能测试,我们总结出以下一些结论
1. Php的函数调用开销相对较大。
2. 函数相关信息保存在一个大的hash_table中,每次调用时通过函数名在hash表中查找,因此函数名长度对性能也有一定影响。
3. 函数返回引用没有实际意义
4. 内置php函数性能比用户函数高很多,尤其对于字符串类操作。
5. 类方法、普通函数、静态方法效率几乎相同,没有太大差异
6. 除去空函数调用的影响,内置函数和同样功能的C函数性能基本差不多。
7. 所有的参数传递都是采用引用计数的浅拷贝,代价很小。
8. 函数个数对性能影响几乎可以忽略
因此,对于php函数的使用,有如下一些建议
1. 一个功能可以用内置函数完成,尽量使用它而不是自己编写php函数。
2. 如果某个功能对性能要求很高,可以考虑用扩展来实现。
3. Php函数调用开销较大,因此不要过分封装。有些功能,如果需要调用的次数很多本身又只用1、2行代码就行实现的,建议就不要封装调用了。
4. 不要过分迷恋各种设计模式,如上一条描述,过分的封装会带来性能的下降。需要考虑两者的权衡。Php有自己的特点,切不可东施效颦,过分效仿java的模式。
5. 函数不宜嵌套过深,递归使用要谨慎。
6. 伪函数性能很高,同等功能实现下优先考虑。比如用isset代替array_key_exists
7. 函数返回引用没有太大意义,也起不到实际作用,建议不予考虑。
8. 类成员方法效率不比普通函数低,因此不用担心性能损耗。建议多考虑静态方法,可读性及安全性都更好。
9. 如不是特殊需要,参数传递都建议使用传值而不是传引用。当然,如果参数是很大的数组且需要修改时可以考虑引用传递。
郑重声明:本站内容如果来自互联网及其他传播媒体,其版权均属原媒体及文章作者所有。转载目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。



































